
🚀 این ChatGPT دیگه چیه که دنیا رو ترکونده؟! 🤯
👋 سلام به همه رفقای باحال و کنجکاو! آخرای سال ۲۰۲۲ بود که یهو یه غول جدید به اسم ChatGPT از راه رسید. باورتون میشه فقط تو دو ماه، ۱۰۰ میلیون نفر کاربر پیدا کرد؟ یعنی رکورد سرعت رشد رو تو تاریخ اینترنت زد و ترکوند! 😎 (جهت اطلاع: تیکتاک ۹ ماه و اینستا ۲.۵ سال تو راه بودن تا به اینجا برسن!) الحق که هرچی از خفن بودنش بگن، کم گفتن!
این مدلهای زبان بزرگ یا همون LLMها، دارن همه چیز رو زیر و رو میکنن. دیگه لازم نیست برای پیدا کردن جواب یه سوال، کل گوگل رو شخم بزنی. خیلی راحت ازش میپرسی و برات توضیح میده. به جای اینکه تو سایتای فنی دنبال کد بگردی، میگی: "داداش، یه کد لازم دارم که این کارو بکنه" و اونم برات مینویسه! یعنی یه جورایی دستیار شخصی همه کاره خودته! 🛠️
حالا فکرشو بکنین چند سال دیگه چی میشه! احتمالاً در طول روز کلی با این هوش مصنوعیا گپ میزنین. از پشتیبانی فنی اینترنتتون گرفته تا دستگاه خودپرداز سر کوچه! 🤖 این دستیارای هوشمند براتون خبرای مهم رو خلاصه میکنن، ایمیلهاتونو جواب میدن و حتی میرن براتون بلیط هواپیما و هتل رزرو میکنن! ✈️🛒
✨ داستان چیه؟ چرا اینقدر کارشون درسته؟
راستشو بخواید، اینا مثل جادو میمونن! یه نویسنده خیلی خفن به اسم آرتور سی. کلارک یه حرف قشنگی زده: «هر تکنولوژی خیلی پیشرفتهای، با جادو فرقی نداره.» هدف ما هم اینه که این جادو رو براتون رمزگشایی کنیم و بگیم پشت پرده چه خبره. در واقع، کلید رام کردن این جادوگر دست خودمونه: با چیزی به اسم «پرامپت» (Prompt) یا همون دستوری که بهش میدیم.
👨💻 داستان ۲ تا برنامهنویس که با این جادو روبرو شدن
این دو نفر از اولین کسایی بودن که روی دستیار کدنویسی GitHub Copilot کار کردن. ببینید خودشون چی میگن:
آلبرت: وقتی آرزومون یهو واقعی شد!
«سالها بود که تولید خودکار کد برامون یه آرزوی محال بود. تا اینکه یه روز یه نمونه اولیه از هوش مصنوعی به دستم رسید. دیدم آینده همین الانه! این مدل فقط کلمه حدس نمیزد، کل یه تابع رو از روی توضیحات فارسی ما مینوشت! و کدهاش عین ساعت کار میکردن! 🤯 همونجا فهمیدیم یه غول چراغ جادو پیدا کردیم که قراره دنیای کدنویسی رو بترکونه.»
جان: وقتی هوش مصنوعی مغزمو سوت کشوند! 💥
«یه روز گفتم بذار یه کار سخت بهش بدم. میخواستم یه کد پیچیده به زبان Rust بنویسم که هیچی ازش بلد نبودم. فقط چند خط راهنمایی به فارسی نوشتم. Copilot نه تنها داشت بهم کد یاد میداد، بلکه یهو یه جایی که گیر کرده بودم، خودش ۳۰ خط کد بینقص نوشت و تحویلم داد! رسماً برگام ریخته بود! تو ۴۰ دقیقه کاری رو کردم که شاید تنهایی چند روز طول میکشید!»
📜 مدلهای زبان قدیمیتر: بابابزرگای ChatGPT کین؟
فکر نکنید این مدلهای زبان یهو از آسمون افتادن پایین! اتفاقاً خیلی وقته که وجود دارن. مثلاً همین الان که دارید این متن رو میخونید، اون قابلیتی که تو کیبورد آیفون کلمه بعدی رو حدس میزنه، پشتش یه مدل زبانی به اسم «مدل مارکوف» (Markov model) خوابیده که اولین بار سال ۱۹۴۸ معرفی شد! 🤯 بله، به همین قدمت!
اما مدلهای جدیدتری هم بودن که راه رو برای این انقلاب هوش مصنوعی که امروز میبینیم، صاف کردن. تا حدود سال ۲۰۱۴، خفنترین مدلهای زبانی بر پایه یه معماری به اسم «توالی به توالی» (sequence to sequence) یا همون seq2seq بودن که تو گوگل توسعه داده شد. این مدل یه نوع شبکه عصبی بازگشتی بود؛ یعنی کلمهها رو دونه دونه میخوند و اطلاعاتش رو آپدیت میکرد که برای کار با متن عالی به نظر میرسید.
این مدل seq2seq برای کارهایی مثل ترجمه، خلاصهسازی، و دستهبندی متنها خیلی خوب بود، اما یه پاشنه آشیل یا نقطه ضعف خیلی بزرگ داشت: یه چیزی به اسم «گلوگاه اطلاعات» که جلوی پیشرفتش رو میگرفت.
معماری Seq2Seq چطور کار میکرد؟ (خیلی ساده!)
این معماری دو تا بخش اصلی داشت: یه انکودر (Encoder) یا «رمزگذار» و یه دیکودر (Decoder) یا «رمزگشا».
- انکودر: جمله ورودی رو کلمه به کلمه میخوند و سعی میکرد کل معنی و مفهوم جمله رو تو یه فایل فشرده به اسم «بردار فکر» (thought vector) خلاصه کنه.
- دیکودر: این «بردار فکر» رو تحویل میگرفت و با استفاده از اون، جمله خروجی رو کلمه به کلمه تولید میکرد (مثلاً ترجمه میکرد).
مشکل اصلی کجا بود؟ اون «بردار فکر» یه حجم ثابت و محدود داشت. برای جملههای طولانی، مثل این بود که بخوای کل کتاب شاهنامه رو تو یه جمله خلاصه کنی! 😅 کلی اطلاعات مهم و جزئیات از قلم میافتاد و دیکودر بیچاره اطلاعات کافی برای تولید یه خروجی خوب نداشت. به این میگن گلوگاه اطلاعات.
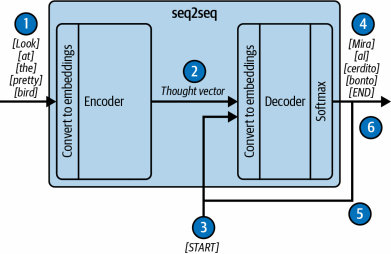
مراحل کار یه مدل ترجمه Seq2Seq به زبان ساده
بذارید دقیقتر ببینیم پشت پرده چه اتفاقی میافتاد:
- کلمههای جمله اصلی (مثلاً فارسی) دونه دونه وارد انکودر میشن.
- انکودر همه اینا رو هضم میکنه و عصارهاش رو تو قالب «بردار فکر» بستهبندی میکنه و میفرسته برای دیکودر.
- یه توکن مخصوص «شروع» به دیکودر میگه: "خب، کارت رو شروع کن!".
- دیکودر با توجه به «بردار فکر»، اولین کلمه ترجمه شده (مثلاً انگلیسی) رو تولید میکنه.
- حالا همین کلمه تولید شده، دوباره به عنوان ورودی به خود دیکودر داده میشه تا کلمه بعدی رو حدس بزنه. این مرحله هی تکرار میشه.
- این داستان ادامه داره تا اینکه دیکودر یه توکن مخصوص «پایان» تولید کنه و بگه "ترجمه تموم شد!". مشکل اینجا بود که اون «بردار فکر» محدود، نمیتونست اطلاعات زیادی رو به دیکودر منتقل کنه و ترجمهها اغلب بیکیفیت میشدن.
🎯 راه حل جادویی از راه رسید: مکانیزم توجه (Attention)!
در سال ۲۰۱۵، یک مقاله انقلابی با عنوان «ترجمه ماشینی عصبی با یادگیری همزمان ترازبندی و ترجمه» یک راه حل خلاقانه برای مشکل «گلوگاه اطلاعات» ارائه داد. ایده اصلی خیلی هوشمندانه بود: به جای اینکه انکودر کل مفهوم جمله رو به زور در یک «بردار فکر» فشرده کنه، تمام اطلاعاتی که برای هر کلمه به دست آورده بود رو نگه میداشت!
بعد به دیکودر اجازه میداد که یک «جستجوی نرم» انجام بده. یعنی چی؟ یعنی دیکودر موقع ترجمه هر کلمه، میتونست به عقب نگاه کنه و به تمام کلمات جمله اصلی «توجه» کنه و ببینه کدوم کلمهها برای ترجمه این قسمت خاص مهمترن. این تکنیک که اسمش رو گذاشتن «مکانیزم توجه» (Attention Mechanism)، کیفیت ترجمه رو به شدت بالا برد. 🤯
مقاله سرنوشتساز: "توجه، تنها چیزی است که نیاز دارید!"
این مکانیزم توجه اونقدر سر و صدا کرد که در سال ۲۰۱۷، محققان گوگل یک مقاله افسانهای به اسم "Attention Is All You Need" منتشر کردن. این مقاله، معماری جدیدی به اسم «ترنسفورمر» (Transformer) رو معرفی کرد.
ترنسفورمر هنوز همون ساختار کلی انکودر-دیکودر رو داشت، اما یک کار انقلابی کرده بود: تمام مدارهای بازگشتی (یعنی پردازش کلمه به کلمه و پشت سر هم) رو حذف کرده بود و به جاش، کاملاً و صددرصد به مکانیزم توجه تکیه کرده بود.
یک پیشرفت بزرگ با یک محدودیت جدید!
نتیجه فوقالعاده بود. معماری ترنسفورمر خیلی انعطافپذیرتر بود و خیلی بهتر از مدلهای قبلی دادهها رو یاد میگرفت. اما یه مشکل جدید به وجود اومد: مدلهای قدیمی seq2seq (حداقل در تئوری) میتونستن متنهایی با هر طولی رو پردازش کنن. اما ترنسفورمر فقط میتونست یک تعداد ثابت و محدودی از کلمات رو به عنوان ورودی و خروجی پردازش کنه.
و از اونجایی که ترنسفورمرها، پدر مستقیم مدلهای GPT (مثل همین ChatGPT) هستن، این محدودیت «پنجره ثابت» چیزیه که محققان از اون روز تا همین الان دارن سعی میکنن باهاش بجنگن و بزرگترش کنن.
💥 انفجار بزرگ: تولد مهندسی پرامپت و مسابقه غولها!
در سال ۲۰۲۰، یک مقاله مهم دیگه به اسم «مدلهای زبان، یادگیرندههای چند-نمونهای هستند» منتشر شد. این مقاله یک کشف شگفتانگیز کرده بود: اگه فقط چندتا مثال از کاری که میخوای مدل انجام بده رو بهش نشون بدی (به این میگن «یادگیری چند-نمونهای» یا Few-shot)، مدل الگو رو یاد میگیره و میتونه تقریباً هر کار دیگهای که ازش بخوای رو با همون الگو و با کیفیت فوقالعاده بالا انجام بده!
اینجا بود که ما فهمیدیم میتونیم با تغییر دادن ورودی یا همون «پرامپت»، مدل رو شرطی کنیم تا دقیقاً کاری که تو ذهن ماست رو انجام بده. این لحظه، لحظه تولد رسمی «مهندسی پرامپت» (Prompt Engineering) بود. ✨
نوامبر ۲۰۲۲، ChatGPT که بر پایه مدل GPT-3.5 ساخته شده بود، منتشر شد و... بقیهاش رو هم که خودتون در تاریخ ثبت کردید! اما این تاریخ، خیلی سریع در حال ساخته شدنه. فقط چند ماه بعد، در مارس ۲۰۲۳، مدل GPT-4 از راه رسید که شایعه شده بود هم از نظر اندازه و هم دادههای آموزشی، چندین برابر بزرگتر و قدرتمندتر از نسل قبلی خودشه.
از اون به بعد، مسابقه رسماً شروع شد! 🏁 یهو همه غولهای تکنولوژی وارد میدون شدن. مدل Llama از شرکت متا (فیسبوک)، Claude از شرکت Anthropic و Gemini از گوگل، همه و همه وارد رقابت شدن. سرعت پیشرفت نه تنها کم نشده، بلکه هر روز داره بیشتر هم میشه!
جدول مقایسه رشد نجومی مدلهای سری GPT
| مدل | تاریخ انتشار | تعداد پارامترها | دادههای آموزشی | هزینه تخمینی آموزش |
|---|---|---|---|---|
| GPT-1 | ۲۰۱۸ | ۱۱۷ میلیون | ۴.۵ گیگابایت متن (از ۷,۰۰۰ کتاب) | 1.7e19 FLOPs |
| GPT-2 | ۲۰۱۹ | ۱.۵ میلیارد | ۴۰ گیگابایت متن (از ۸ میلیون صفحه وب) | 1.5e21 FLOPs |
| GPT-3 | ۲۰۲۰ | ۱۷۵ میلیارد | ~۵۷۰ گیگابایت متن (۴۹۹ میلیارد توکن) | 3.1e23 FLOPs |
| GPT-3.5 | ۲۰۲۲ | ۱۷۵ میلیارد | نامشخص | نامشخص |
| GPT-4 | ۲۰۲۳ | ۱.۸ تریلیون (شایعه) | ۱۳ تریلیون توکن (شایعه) | ~2.1e25 FLOPs |
همونطور که میبینید، این رشد کاملاً نجومیه! 🚀
🤔 اون ستون عجیب «هزینه آموزش» (FLOPs) یعنی چی؟
حتماً با دیدن اون عددهای عجیب و غریب تو ستون آخر، حسابی کنجکاو شدید! بذارید خیلی ساده و خودمونی بگم اینا چی هستن.
- FLOPs یعنی چی؟ خیلی ساده: تعداد کل محاسبات ریاضی که کامپیوترها برای آموزش دادن یه مدل انجام دادن. هرچی این عدد بزرگتر باشه، یعنی اون مدل گرسنهتر بوده و غذای (پردازش) بیشتری مصرف کرده! 🍔
- یه مثال خیلی ساده! فکر کنید دارید با ماشین از تهران به شمال میرید.
- قدرت کامپیوتر (پردازنده) مثل سرعت ماشین شماست (مثلاً ۱۲۰ کیلومتر بر ساعت).
- هزینه آموزش (FLOPs) مثل کل بنزینیه که تو این سفر مصرف کردید (مثلاً ۳۰ لیتر).
- اون عددهای عجیب (e23) چی هستن؟ این یه روش خلاصه برای نوشتن عددهای خیلی بزرگه. مثلاً وقتی مینویسه
3.1e23، یعنی عدد ۳۱ با ۲۲ تا صفر جلوش! یه عدد فضایی که حتی تصورش هم سخته! 🤯
پس، ستون «هزینه آموزش» داره به ما میگه که دانشمندا برای ساختن و آموزش دادن هر مدل، چقدر کار محاسباتی از کامپیوترها کشیدن. این اعداد به خوبی نشون میدن که چرا ساخت این مدلها انقدر گرون و پیچیدهست و فقط شرکتهای بزرگ از پسش برمیان!
🎨 مهندسی پرامپت: هنر صحبت کردن با غول چراغ جادو!
خب، رسیدیم به اول سفر هیجانانگیزمون تو دنیای مهندسی پرامپت. ته تهش، این مدلهای زبان بزرگ (LLM) فقط یه کار بلدن: کامل کردن متن. به متنی که به مدل میدیم میگن «پرامپت» (Prompt). پس مهندسی پرامپت، تو سادهترین حالتش، یعنی هنر ساختن یه پرامپت حرفهای که مدل با کامل کردنش، دقیقاً جوابی که لازم داریم رو بهمون بده.
اما تو این کتاب، ما یه نگاه خیلی بزرگتر به ماجرا داریم و فراتر از ور رفتن با یه پرامپت ساده میریم. ما در مورد ساختن یک اپلیکیشن کامل مبتنی بر LLM صحبت میکنیم. در این اپلیکیشن، یک حلقه ارتباطی هوشمند بین کاربر، اپلیکیشن و مدل وجود داره:
- کاربر مشکلش رو به اپلیکیشن میگه.
- اپلیکیشن حرفهای کاربر رو به یه «سند» یا پرامپت قابل فهم برای مدل تبدیل میکنه.
- مدل (LLM) اون سند رو کامل میکنه.
- اپلیکیشن دوباره جواب مدل رو میگیره، تجزیه و تحلیل میکنه و نتیجه رو به شکلی که برای کاربر قابل فهم باشه، بهش نشون میده.
سطحهای مختلف مهندسی پرامپت: از آماتور تا حرفهای! 🚀
مهندسی پرامپت چندین سطح داره:
- 1️⃣ سطح پایه: اینجا تقریباً شما مستقیم با مدل حرف میزنید. مثلاً وقتی تو خود ChatGPT یه سوال میپرسید، اپلیکیشن فقط حرفهای شما رو تو یه قالب خاص بستهبندی میکنه و میفرسته برای مدل.
- 2️⃣ سطح متوسط (غنیسازی پرامپت): اینجا اپلیکیشن قبل از فرستادن پرامپت، اون رو هوشمندتر میکنه. مثلاً:
- 🎤 اضافه کردن اطلاعات: یه پشتیبانی تلفنی میتونه صدای شما رو به متن تبدیل کنه و به پرامپت اضافه کنه. یا مثلاً موتور جستجوی بینگ، نتایج جستجوی وب رو به پرامپت اضافه میکنه تا مدل در مورد اتفاقات جدید هم بتونه حرف بزنه و کمتر «توهم» بزنه!
- 🧠 حفظ کردن حافظه (Stateful): اینجا اپلیکیشن مکالمههای قبلی رو یادش میمونه (مثل چتباتها). چالش اصلی اینه که چطور خلاصهای از گذشته رو تو پرامپت جا بدیم که هم مدل گیج نشه و هم پرامپت بیش از حد طولانی نشه.
- 3️⃣ سطح پیشرفته (دادن ابزار به مدل): 🔧 در این سطح، ما به اپلیکیشن «ابزار» میدیم تا بتونه با دنیای واقعی تعامل کنه. مثلاً بهش میگی: «برای دوستم یه دعوتنامه جلسه بفرست.» اپلیکیشن از یه ابزار برای پیدا کردن ایمیل دوستت استفاده میکنه، با یه ابزار دیگه تقویمش رو چک میکنه و در نهایت با یه ابزار سوم، ایمیل رو ارسال میکنه!
- 4️⃣ سطح نهایی (دادن قدرت تصمیمگیری): 🤖 به این میگن «عاملیت» (Agency). یعنی مدل خودش برای رسیدن به یه هدف بزرگ، تصمیم میگیره که چه کارهایی رو مرحله به مرحله انجام بده. ابزاری مثل AutoGPT سعی در انجام این کار داره. همیشه موفق میشه؟ نه! راستش بیشتر وقتا شکست میخوره. اما این، قدم مهمی به سمت آینده هیجانانگیز هوش مصنوعیه.
🏁 حرف آخر و جمعبندی
همونطور که اول گفتیم، این فصل یه جورایی پیشزمینه سفر ما بود. ما تاریخچه مدلهای زبان رو مرور کردیم و فهمیدیم چرا LLMها اینقدر خاص و متفاوتن. بعد هم موضوع اصلی کتاب رو تعریف کردیم: مهندسی پرامپت.
یادتون باشه، هدف این کتاب فقط این نیست که یاد بگیریم چطور با کلمات بازی کنیم تا یه جواب خوب از مدل بگیریم. هدف ما اینه که یاد بگیریم چطور یک اپلیکیشن کامل مبتنی بر LLM بسازیم. اپلیکیشنی که مثل یه مترجم حرفهای، نیازهای دنیای واقعی رو به زبان قابل فهم برای مدلها تبدیل میکنه و جواب اونها رو به اطلاعات و اقدامات کاربردی برای ما برمیگردونه.
آماده سفر هستید؟ 🎒
قبل از اینکه دل رو به جاده بزنیم، بذارید مطمئن شیم کولهپشتیمون رو درست بستیم. تو فصل بعدی، یاد میگیریم که این مدلها چطور متن رو کامل میکنن (از سطح بالا تا ریزترین جزئیات). بعدش میبینیم که چطور همین قابلیت ساده، بهشون اجازه میده تا چت کنن و از ابزارها استفاده کنن. وقتی این پایهها رو خوب یاد گرفتیم، برای شروع سفر اصلی آمادهایم!
```





