
فصل چهارم: ساخت اپلیکیشن با LLMها (جادوگری شروع میشه!) ✨
خب رفقا، تا اینجا فونداسیون کار رو ریختیم! تو فصلهای قبل فهمیدیم که این مدلهای زبان بزرگ (LLM) ته تهش یه کار خیلی خفن بلدن: کامل کردن متن. دیدیم که حتی ChatGPT با اون همه ابهتش، در واقع داره یه صورتجلسه گفتگو رو کامل میکنه. انگار یه نویسنده خیلی سریع و خلاق کنار دستمونه.
از اینجا به بعد، قراره یاد بگیریم چطور از این نویسنده خلاق استفاده کنیم و اپلیکیشنهای واقعی بسازیم که مشکلات واقعی رو حل کنن. این فصل، دروازه ورود به دنیای جادوگری ماست!
اپلیکیشن LLM چیه؟ یه مترجم جادویی! 🧙♂️
فکر کنید دوتا دنیا داریم: یکی دنیای ما آدمها که پر از مشکل و نیازه (مثلاً «میخوام برای دوستم یه ایمیل باحال بنویسم») و یکی هم دنیای مدل هوش مصنوعی که فقط یه زبان بلده: «کامل کردن متن».
اپلیکیشنی که ما میسازیم، مثل یه مترجم جادویی بین این دوتا دنیا عمل میکنه. کارش اینه که مشکل ما رو از دنیای خودمون بگیره، به زبانی که مدل میفهمه (یعنی یه متن ناقص) ترجمه کنه، بده به مدل تا کاملش کنه، و بعد جواب مدل رو دوباره برای ما ترجمه کنه و به شکل یه راه حل تحویلمون بده.
۱. شما (در دنیای آدمها): «ایمیل به دوستم: تبریک تولد، آرزوی موفقیت، قرار کافه»
⬇️
۲. اپلیکیشن (مترجم جادویی): اینو به یه متن ناقص تبدیل میکنه: «موضوع: تولدت مبارک! سلام رفیق، خواستم تولدت رو تبریک بگم و...»
⬇️
۳. مدل (در دنیای متن): متن رو کامل میکنه: «...و برات بهترینها رو آرزو کنم. امیدوارم همیشه موفق باشی. راستی، پایهای این هفته یه سر بریم کافه؟»
⬇️
۴. اپلیکیشن (مترجم جادویی): این متن کامل رو به شما نشون میده تا ارسالش کنید.
به این چرخه رفت و برگشت میگیم حلقه تعامل (The Loop).
این حلقه میتونه فقط یک بار اجرا بشه (مثل همین مثال ایمیل) یا میتونه بارها و بارها تکرار بشه و اطلاعات قبلی رو هم یادش بمونه (مثل یه چتبات که باهاش حرف میزنید).
در بخشهای بعدی، قراره قدم به قدم این مترجم جادویی رو با هم بسازیم. از گرفتن مشکل کاربر گرفته تا تحویل دادن یه راه حل کامل. آمادهاید که آستینها رو بالا بزنید؟
قدم اول حلقه: درک مشکل کاربر 🧐
حلقه تعامل ما همیشه از کاربر و مشکلی که میخواد حل کنه، شروع میشه. مشکلات کاربرا میتونن از خیلی ساده تا خیلی پیچیده متغیر باشن. برای اینکه بتونیم یه اپلیکیشن خوب بسازیم، اول باید ابعاد مختلف این پیچیدگی رو بشناسیم. مهمترین ابعاد اینا هستن:
- رسانه (Medium): کاربر از چه طریقی با ما حرف میزنه؟ متن؟ صدا؟ یا تعاملات پیچیده تو یه وبسایت؟ (طبیعتاً متن برای LLMها از همه راحتتره).
- سطح انتزاع (Abstraction): مشکل چقدر کلی و مبهمه؟ یه مشکل مشخص مثل «غلطهای املایی این متن رو بگیر» خیلی سادهتر از یه مشکل انتزاعی مثل «برام یه سفر خوب برنامهریزی کن» هست.
- اطلاعات زمینهای (Context): برای حل مشکل، به چه اطلاعات اضافهای (غیر از حرفهای خود کاربر) نیاز داریم؟ مثلاً برای پشتیبانی فنی، به دفترچههای راهنما نیاز داریم.
- حافظهدار بودن (Statefulness): آیا اپلیکیشن باید تعاملات قبلی رو یادش بمونه؟ یه چتبات باید حافظه داشته باشه، ولی یه ابزار ساده غلطگیر املایی نیازی به حافظه نداره.
مقایسه سه سناریو: از ساده تا پیچیده
بیاید این ابعاد پیچیدگی رو تو سه تا سناریوی مختلف با هم مقایسه کنیم:
| بعد پیچیدگی | ساده: غلطگیر املایی | متوسط: پشتیبانی فنی | پیچیده: برنامهریز سفر |
|---|---|---|---|
| رسانه | متن | صدا (تماس تلفنی) | تعاملات وبسایت، متن، API |
| سطح انتزاع | مشکل کاملاً مشخص و کوچک | مشکل بزرگ ولی محدود به مستندات | درک سلیقههای شخصی و محدودیتهای عینی برای یه راه حل پیچیده |
| اطلاعات زمینهای | فقط متن خود کاربر | دسترسی به مستندات فنی و نمونههای قبلی | دسترسی به تقویم، API ایرلاینها، اخبار، ویکیپدیا و... |
| حافظهدار بودن | بدون حافظه (هر درخواست مستقله) | باید تاریخچه گفتگو و راهحلهای امتحان شده رو یادش بمونه | باید تعاملات رو در طول هفتهها و شاخههای مختلف برنامهریزی، یادش بمونه |
همونطور که میبینید، یه اپلیکیشن غلطگیر از همه نظر ساده است، در حالی که یه برنامهریز سفر فوقالعاده پیچیدهست. به عنوان یه مهندس پرامپت، وظیفه ما اینه که برای هر کدوم از این ابعاد پیچیدگی، یه راه حل هوشمندانه پیدا کنیم. در ادامه این کتاب، با جزئیات کامل به این راه حلها خواهیم پرداخت.
قدم دوم حلقه: ترجمه مشکل کاربر به زبان مدل 🗣️
خب، رسیدیم به بخش اصلی کار ما به عنوان مهندس پرامپت. اینجا جاییه که مشکل کاربر رو به دنیای مدل ترجمه میکنیم. هدف ما اینه که یه پرامپت بسازیم که مدل با کامل کردنش، اطلاعاتی رو به ما بده که مشکل کاربر رو حل کنه. ساختن یه پرامپت بینقص، کار سادهای نیست و باید همزمان چهارتا معیار مهم رو رعایت کنیم:
چهار فرمان مهندسی پرامپت:
- پرامپت باید خیلی شبیه به چیزایی باشه که مدل قبلاً تو آموزشش دیده.
- پرامپت باید تمام اطلاعات لازم برای حل مشکل رو شامل بشه.
- پرامپت باید مدل رو به سمت دادن یه راه حل (و نه فقط حرف زدن در مورد مشکل) هدایت کنه.
- جواب مدل باید یه نقطه پایان منطقی داشته باشه تا الکی ادامه پیدا نکنه.
بیاید هر کدوم از این معیارها رو با هم باز کنیم.
فرمان اول: اصل شنل قرمزی! 🐺
داستان شنل قرمزی رو که یادتونه؟ یه دختر ساده با یه لباس قرمز خوشگل که داشت از مسیر جنگل میرفت خونه مادربزرگش. با اینکه مامانش کلی بهش هشدار داده بود، دختر قصه ما از مسیر اصلی خارج شد و گیر یه گرگ بدجنس افتاد و... خلاصه که داستان خیلی ترسناک شد! واقعاً عجیبه که ما این داستانا رو برای بچهها تعریف میکنیم!
اما نکتهای که برای ما مهمه، خیلی ساده است: از مسیری که مدل روش آموزش دیده، خیلی دور نشید! هر چی پرامپت شما واقعیتر، طبیعیتر و شبیهتر به متنهایی باشه که مدل قبلاً دیده (مثل مقالههای ویکیپدیا، کدهای برنامهنویسی، گفتگوهای چت)، احتمال اینکه جواب مدل قابل پیشبینی و باثبات باشه، بیشتره. پس همیشه سعی کنید از الگوهای رایج در دادههای آموزشی تقلید کنید.
چطور بفهمیم مدل با چه نوع متنهایی آشناست؟
از خودش بپرسید! مثلاً این پرامپت رو امتحان کنید: «چه نوع اسناد رسمی برای مشخص کردن اطلاعات مالی یه شرکت مفیدن؟» مدل یه لیست بلند بالا از انواع اسنادی که میشناسه بهتون میده که میتونید ازشون الگوبرداری کنید.
یک مثال عملی: تبدیل مشکل کاربر به یه مسئله تکلیف درسی! 📝
بیاید تمام این چهار فرمان رو تو یه مثال عملی ببینیم. فرض کنید میخوایم یه اپلیکیشن ساده پیشنهاد سفر بسازیم. ما پرامپت رو جوری طراحی میکنیم که شبیه به یه تکلیف درسی باشه (یادتونه؟ اصل شنل قرمزی!). این مثال از API تکمیل متن استفاده میکنه تا بتونیم تمام جزئیات رو بهتر ببینیم.
(توجه: ساخت یه اپلیکیشن سفر واقعی خیلی پیچیدهتر از اینه! این فقط یه مثال ساده برای نشون دادن مفاهیمه).
نمونه پرامپت برای اپلیکیشن پیشنهاد سفر
# تکلیف درس گردشگری ۱۰۱
به سه سوال زیر پاسخ دهید. هر پاسخ باید کوتاه و مختصر باشد (حداکثر یک یا دو جمله).
## سوال ۱
سه مقصد برتر گلف برای پیشنهاد به مشتریان کدامند؟ پاسخ را در یک جمله کوتاه ارائه دهید.
## جواب ۱
سنت اندروز در اسکاتلند، پبل بیچ در کالیفرنیا و آگوستا در جورجیا، مقاصد عالی برای گلف هستند.
## سوال ۲
فرض کنید مشتری از شما میخواهد برای سفر به پیونگیانگ، کره شمالی به او کمک کنید.
شما توصیههای وزارت خارجه را چک میکنید و میبینید که نوشته: «به دلیل خطر جدی دستگیری و بازداشت طولانی مدت شهروندان، به کره شمالی سفر نکنید.»
شما اخبار اخیر را چک میکنید و این تیترها را میبینید:
- «کره شمالی موشک بالستیک شلیک کرد»
- «قرنطینه پنج روزه کووید-۱۹ در پیونگیانگ اعمال شد»
- «تلاشهای جدید برای رسیدگی به وضعیت وخیم حقوق بشر در کره شمالی»
لطفاً یک توصیه کوتاه برای سفر به مقصد مورد نظر مشتری ارائه دهید. به مشتری چه میگویید؟
## جواب ۲
(اینجا جایی است که مدل جوابش را تولید میکند)
تکمیل احتمالی مدل:
شاید کره شمالی در حال حاضر مقصد خوبی نباشد. اما شرط میبندم میتوانیم یک جای خوب برای بازدید در کره جنوبی پیدا کنیم.
کالبدشکافی پرامپت بالا:
- فرمان اول (اصل شنل قرمزی): اول از همه، پرامپت ما شبیه به یه تکلیف درسیه؛ یه نوع سندی که مدل قبلاً هزاران بار تو دادههای آموزشی دیده. ما داریم تو مسیر آشنای مدل حرکت میکنیم. همچنین از مارکداون (مثل `##`) استفاده کردیم که به مدل کمک میکنه ساختار رو بهتر بفهمه.
- فرمان دوم (اطلاعات کامل): تمام اطلاعات زمینهای که برای جواب دادن لازمه رو به پرامپت اضافه کردیم: درخواست کاربر (کره شمالی)، توصیههای سفر و اخبار اخیر.
- فرمان سوم (هدایت به راه حل): ما با آوردن یه سوال و جواب نمونه (`سوال ۱` و `جواب ۱`)، یه الگو برای مدل تعریف کردیم. این به مدل یاد میده که اولاً باید یه جواب کوتاه و مؤدبانه بده و ثانیاً، بعد از هر `سوال`، باید یه `جواب` بیاد. در نهایت، با نوشتن `## جواب ۲`، به وضوح به مدل میفهمونیم که وقت جواب دادنه! اگه این رو نمینوشتیم، مدل احتمالاً شروع میکرد به پرحرفی کردن در مورد کره شمالی.
فرمان چهارم: به مدل بگویید کی ساکت شود! 🤫
ما باید کاری کنیم که جواب مدل یه نقطه پایان منطقی داشته باشه و الکی ادامه پیدا نکنه و از خودش داستان نبافه. باز هم تو مدلهای چت این کار ساده است، چون اونا یاد گرفتن که بعد از جواب دادن، تمومش کنن.
اما تو مدلهای تکمیل متن، ما باید یه «کلمه رمز توقف» براش تعریف کنیم. منطقش اینه:
ما تو پرامپتمون یه الگو ساختیم: هر بخش جدید (مثل سوال یا جواب) با `##` شروع میشه. پس میتونیم به مدل بگیم: «هر وقت خواستی یه متنی بنویسی که با دوتا علامت شارپ (`##`) شروع میشه، دست نگه دار و دیگه ادامه نده!»
این کار رو با استفاده از پارامتری به اسم stop موقع ارسال درخواست به API انجام میدیم. ما بهش میگیم کلمه رمز توقف ما، `##` هست. اینطوری، اگه مدل جواب سوال ۲ رو داد و بعدش خواست از خودش یه `## سوال ۳` در بیاره، به محض تایپ کردن اون دوتا علامت شارپ، تولید متن متوقف میشه. این یه ترفند خیلی کاربردی برای کنترل کردن طول و محتوای خروجیه.
چرا مدل از خودش سوال طرح میکنه؟! 🤔
شاید بپرسید «مگه ما خودمون سوال رو بهش نمیدیم؟». دقیقاً! اما یادتون باشه، مدل نمیفهمه که این سوال شماست. اون فقط یه الگوی متنی رو میبینه: "سوال - جواب - سوال - جواب".
از دید مدل، محتملترین ادامه برای الگویی که دیده، شروع کردن یه سوال جدیده! اون نمیدونه که سوالها تموم شدن. پارامتر `stop` مثل یه ترمز دستی عمل میکنه و به مدل میگه: «هر وقت خواستی این الگو رو دوباره تکرار کنی، ترمز کن! کارت تمومه.»
مدلهای چت در مقابل مدلهای تکمیل متن: کدوم راحتتره؟
تو مثالی که زدیم، ما از یه مدل تکمیل متن استفاده کردیم تا اون چهار فرمان رو بهتر نشون بدیم. اما با اومدن مدلهای چت، خیلی از این کارها سادهتر شده. چرا؟
- مدلهای چت به صورت خودکار ورودی شما رو به یه صورتجلسه گفتگو (ChatML) تبدیل میکنن، پس فرمان اول (اصل شنل قرمزی) تا حد زیادی رعایت میشه.
- این مدلها آموزش دیدهان که همیشه به عنوان یه دستیار، به مشکل کاربر جواب بدن، پس فرمان سوم (هدایت به راه حل) هم خود به خود انجام میشه.
- همچنین یاد گرفتن که بعد از جواب دادن، حرفشون رو تموم کنن، پس فرمان چهارم (نقطه پایان) هم حله!
اما این به این معنی نیست که شما به عنوان مهندس پرامپت، دیگه بیکار شدید! 😉
شما هنوز مسئول اصلی اجرای فرمان دوم (فراهم کردن تمام اطلاعات لازم) هستید. همچنین باید پیام سیستم و کل صورتجلسه گفتگو رو طوری طراحی کنید که مدل به بهترین شکل ممکن مشکل کاربر رو حل کنه.
💡 حالا نوبت شماست! (چندتا تمرین باحال)
با یه مدل تکمیل متن (مثل gpt-3.5-turbo-instruct)، همون پرامپت تکلیف درسی رو امتحان کنید و ببینید با این تغییرات چه اتفاقی میفته:
- اگه `## جواب ۲` رو حذف کنید چی میشه؟ آیا مدل هنوز جواب میده یا شروع میکنه به پرحرفی در مورد مشکل؟
- جواب سوال ۱ (که نمونه ما بود) رو تغییر بدید. مثلاً خیلی طولانیش کنید یا با لحن دزدای دریایی بنویسید! 🏴☠️ آیا این تغییر روی لحن و طول جواب سوال ۲ تاثیر میذاره؟
- همون کره شمالی رو نگه دارید، ولی به جای اخبار و هشدارهای منفی، چندتا نکته مثبت در موردش بنویسید. آیا مدل هنوز هم سفر به اونجا رو پیشنهاد نمیکنه؟ چرا؟ (این به بایاسهای داخل مدل ربط داره).
- پارامتر `stop` رو حذف کنید. آیا مدل از خودش یه «سوال ۳» الکی میسازه؟
- به نظرتون استفاده از قالب «تکلیف درسی» ممکنه هیچ ایرادی داشته باشه؟ (مثلاً ممکنه لحن مدل رو زیادی رسمی و خشک کنه؟)
قدم سوم حلقه: اجرای پرامپت و گرفتن جواب از مدل 🚀
خب، حالا که پرامپتمون رو مثل یه کارگردان حرفهای آماده کردیم، وقتشه که اون رو برای مدل بفرستیم و منتظر جوابش بمونیم. شاید اگه فقط با ChatGPT کار کرده باشید، فکر کنید اینجا کار خاصی نباید انجام داد. اما در دنیای واقعی، اینجا چندتا تصمیم خیلی مهم باید بگیرید، چون همه مدلها مثل هم نیستن!
مهمترین تصمیمی که باید بگیرید، انتخاب مدل مناسبه. این انتخاب، یه بدهبستان بین چندتا فاکتور مهمه:
معیارهای انتخاب مدل:
- کیفیت در مقابل هزینه (Cost): معمولاً هر چی مدل بزرگتر و قویتر باشه (مثل GPT-4)، جوابهای باکیفیتتری میده. اما هزینهاش هم به شدت بالاتره! در حال حاضر، هزینه استفاده از GPT-4 میتونه تا ۲۰ برابر بیشتر از gpt-3.5-turbo باشه. آیا این افزایش کیفیت، به این افزایش هزینه میارزه؟ جواب این سوال کاملاً به پروژه شما بستگی داره. 💰
- سرعت (Latency): مدلهای بزرگتر، محاسبات بیشتری نیاز دارن و طبیعتاً کندتر هستن. کاربر شما چقدر حاضره برای گرفتن جواب منتظر بمونه؟ مثلاً ما در روزهای اولیه ساخت GitHub Copilot، از یه مدل کوچیکتر ولی برقآسا به اسم Codex استفاده کردیم. اگه از GPT-4 استفاده میکردیم، هیچ برنامهنویسی حوصله نداشت اونقدر برای تکمیل کدش صبر کنه، حتی اگه جواب نهایی فوقالعاده بود! ⚡
- تنظیم دقیق (Fine-tuning): گاهی وقتا به جای استفاده از یه مدل غولپیکر و همهکاره، بهتره یه مدل کوچیکتر رو برداریم و اون رو با دادههای تخصصی خودمون «تنظیم دقیق» کنیم. این کار وقتی مفیده که شما میخواید مدل در مورد یه موضوع خیلی خاص (که تو اینترنت اطلاعات زیادی ازش نیست) اطلاعات داشته باشه یا رفتار خاصی از خودش نشون بده. مثلاً ما در گیتهاب، داریم مدلهای Codex رو برای زبانهای برنامهنویسی کمتر رایج، تنظیم دقیق میکنیم تا کیفیت بالاتری ارائه بدن. 🛠️
فرآیند تنظیم دقیق فراتر از حوصله این کتابه، اما مطمئن باشید که در آینده این کار سادهتر و رایجتر میشه، پس حتماً این ابزار رو تو جعبه ابزارتون داشته باشید.
قدم آخر حلقه: ترجمه مجدد جواب مدل به دنیای کاربر! 🎁
خب، به ایستگاه آخر حلقه رسیدیم. جواب مدل یه تیکه متن خامه. اگه دارید یه چتبات خیلی ساده میسازید، شاید کارتون همینجا تموم شده باشه و فقط کافیه همین متن رو به کاربر نشون بدید. اما در اکثر مواقع، شما باید این متن رو پردازش کنید و اطلاعاتش رو استخراج کنید تا برای کاربر نهایی مفید باشه.
در گذشته با مدلهای تکمیل متن، ما مجبور بودیم از مدل بخوایم که اطلاعات رو با یه فرمت خیلی خاص (مثلاً JSON یا XML) بهمون بده و بعد خودمون اون اطلاعات رو از دل متن استخراج (Parse) میکردیم. این کار خیلی سخت و پر از خطا بود.
ظهور مدلهای تابع-خوان (Function-Calling)
خوشبختانه، با اومدن مدلهای تابع-خوان، این کار خیلی خیلی سادهتر شده. منطق کار این مدلها اینه:
- شما به مدل میگید مشکل کاربر چیه.
- یه لیست از «ابزارها» یا «توابع» (Functions) که در اختیار دارید رو بهش معرفی میکنید (مثلاً یه تابع برای چک کردن قیمت بلیط هواپیما).
- از مدل میخواید که به جای جواب دادن مستقیم، اگه لازم بود، یکی از این توابع رو با پارامترهای درست «فراخوانی» کنه.
مثلاً تو اپلیکیشن سفر، مدل به جای اینکه یه متن الکی در مورد بلیط بنویسه، یه خروجی ساختاریافته تولید میکنه که میگه: «تابع `check_flights` رو با مبدا تهران، مقصد پاریس و تاریخ فردا، فراخوانی کن.»
اپلیکیشن شما این درخواست رو میگیره، تابع واقعی رو اجرا میکنه، نتیجه رو (لیست پروازها) میگیره و به شکل زیبایی به کاربر نشون میده. ما تو فصلهای ۸ و ۹ خیلی مفصل در مورد این ابزارها صحبت میکنیم.
تغییر شکل کامل خروجی!
گاهی وقتا ما حتی رسانه ارتباطی رو هم به طور کامل تغییر میدیم. مدل همیشه متن تولید میکنه، اما:
- اگه کاربر داره با یه سیستم پشتیبانی تلفنی حرف میزنه، ما باید اون متن رو به صدا تبدیل کنیم. 🗣️
- اگه کاربر داره با یه رابط کاربری گرافیکی پیچیده کار میکنه، خروجی مدل ممکنه به تغییراتی در UI (مثلاً نمایش یه پنجره جدید) تبدیل بشه. 🖥️
- حتی اگه خروجی نهایی هم متنی باشه، ممکنه لازم باشه شکل نمایشش رو عوض کنیم. مثلاً تو GitHub Copilot، کد پیشنهادی به صورت خاکستری و کمرنگ نشون داده میشه، ولی وقتی از چت Copilot میخواید یه تیکه کد رو تغییر بده، نتیجه به صورت یه مقایسه متنی قرمز/سبز (Diff) نمایش داده میشه.
زوم روی نیمه اول حلقه: آمادهسازی پرامپت 🔬
بیاید یه کم دقیقتر بشیم و روی نیمه اول حلقه تعامل، یعنی همون بخشی که مشکل کاربر رو به زبان مدل ترجمه میکنیم، زوم کنیم. به این فرآیند میگن «مسیر پیشرو» (Feedforward Pass). تقریباً تمام فصلهای باقیمونده این کتاب، در مورد جزئیات همین فرآیند و تکنیکهای مختلف برای گرفتن بهترین جواب از مدله. اما قبل از اینکه وارد جزئیات بشیم، بیاید با چندتا ایده پایهای آشنا بشیم.
مراحل اصلی مسیر پیشرو
این فرآیند از چندتا مرحله اصلی تشکیل شده که در فصلهای بعدی، هر کدوم رو با جزئیات کامل بررسی میکنیم:
۱. جمعآوری اطلاعات زمینهای (Context Retrieval)
⬇️
۲. تکهتکه کردن اطلاعات (Snippetizing)
⬇️
۳. سر هم کردن پرامپت (Prompt Assembly)

قدم اول: جمعآوری اطلاعات زمینهای (Context)
اولین کاری که میکنیم، جمعآوری تمام متنهای خامیه که به عنوان اطلاعات زمینهای برای پرامپت لازم داریم. این اطلاعات رو میشه به سه دسته تقسیم کرد:
- اطلاعات مستقیم: این همون چیزیه که کاربر مستقیماً به ما میگه. مثلاً تو یه اپلیکیشن پشتیبانی فنی، متنیه که کاربر تو چتباکس تایپ میکنه.
- اطلاعات غیرمستقیم: این اطلاعات از منابع مرتبط دیگه به دست میاد. مثلاً تو همون اپلیکیشن پشتیبانی، ما میتونیم تو مستندات فنی دنبال بخشهایی بگردیم که به مشکل کاربر ربط دارن. یا تو GitHub Copilot، اطلاعات غیرمستقیم از تبهای باز دیگه تو محیط برنامهنویسی میاد.
- متنهای کلیشهای (Boilerplate): اینا متنهای ثابتی هستن که ما خودمون برای شکل دادن به پرامپت و هدایت مدل ازشون استفاده میکنیم. مثلاً اول پرامپت مینویسیم: «این یک درخواست پشتیبانی فنی است. ما هر کاری میکنیم تا مشکل کاربر حل شود.» این متنها مثل چسب، تیکههای مختلف اطلاعات رو به هم وصل میکنن.
قدم دوم: تکهتکه کردن اطلاعات (Snippetizing)
بعد از اینکه تمام اطلاعات مرتبط رو جمع کردیم، باید اونها رو تکهتکه و اولویتبندی کنیم. یعنی چی؟ یعنی از بین تمام اطلاعاتی که داریم، فقط مرتبطترین و مهمترین بخشها رو استخراج کنیم. اگه یه جستجو تو مستندات فنی، دهها صفحه نتیجه برگردونه، ما نمیتونیم همه رو تو پرامپت جا بدیم! چون هم ممکنه از محدودیت توکن پرامپت رد بشیم و هم مدل گیج میشه.
گاهی وقتا هم این تکهتکه کردن یعنی تبدیل فرمت. مثلاً اگه اطلاعات ما از یه API به صورت JSON میاد، بهتره اون رو به یه متن روان و قابل فهم برای مدل تبدیل کنیم تا مدل شروع به تولید جوابهای JSONی نکنه!
امتیازدهی و اولویتبندی تکهها (Scoring & Prioritizing)
در گذشته، مدلها پنجره زمینه (Context Window) خیلی کوچیکی داشتن (مثلاً ۴,۰۹۶ توکن) و ما همیشه نگران کمبود جا بودیم. الان با پنجرههای بزرگتر (بالای ۱۰۰,۰۰۰ توکن)، این نگرانی کمتر شده. اما هنوز هم خیلی مهمه که پرامپتهامون رو تا حد ممکن خلوت و مرتبط نگه داریم. چرا؟ چون متنهای طولانی و بیربط، مدل رو گیج میکنن و کیفیت جواب نهایی رو پایین میارن.
برای اینکه بهترین محتوا رو انتخاب کنیم، بعد از اینکه تکههای مختلف اطلاعات رو جمع کردیم، باید به هر کدوم یه اولویت (Priority) یا یه امتیاز (Score) بدیم.
- اولویت: مثل طبقهبندی کردن اطلاعات در چند سطح. مثلاً میگیم «اطلاعات مستقیم کاربر» اولویت ۱ هستن، «مستندات فنی مرتبط» اولویت ۲ و «متنهای کلیشهای» اولویت ۳. موقع ساختن پرامپت، اول تمام تکههای اولویت ۱ رو جا میدیم، اگه جا موند میریم سراغ اولویت ۲ و الی آخر.
- امتیاز: یه عدد اعشاریه که تفاوتهای ظریفتر بین تکهها رو نشون میده. مثلاً بین چندتا تیکه از مستندات فنی (که همهشون اولویت ۲ هستن)، اونی که به کلمات کلیدی کاربر نزدیکتره، امتیاز بالاتری میگیره و زودتر تو پرامپت قرار داده میشه.
قدم سوم: سر هم کردن پرامپت نهایی (Prompt Assembly)
در مرحله آخر، تمام این تکههای اولویتبندی شده، مثل یه پازل کنار هم چیده میشن تا پرامپت نهایی ساخته بشه. تو این مرحله چندتا هدف مهم داریم:
- باید مشکل کاربر رو به وضوح بیان کنیم.
- باید پرامپت رو تا جایی که میشه با بهترین و مرتبطترین اطلاعات زمینهای پر کنیم.
- و مهمتر از همه، باید حواسمون باشه که از بودجه توکنمون بیشتر نشه! وگرنه مدل به جای جواب، فقط یه ارور بهمون برمیگردونه.
اینجا کار ما شبیه به حسابداری میشه! باید حساب کنیم که متنهای کلیشهای چقدر جا میگیرن، درخواست کاربر چقدر جا میگیره و با بقیه فضای باقیمونده، تا جایی که میشه از اطلاعات زمینهای مفید استفاده کنیم.
گاهی وقتا تو این مرحله مجبور میشیم برای جا دادن یه متن مهم، بخشهای کماهمیتترش رو حذف کنیم (Elide) یا حتی از مدل بخوایم که یه متن طولانی رو برامون خلاصهسازی کنه.
در نهایت، تمام این قطعات پازل باید به ترتیب درستی کنار هم قرار بگیرن تا پرامپت نهایی، شبیه به یه متن منسجم و منطقی باشه که شنل قرمزی قصهمون رو مستقیم به خونه مادربزرگ برسونه! 😉
بررسی پیچیدگیهای حلقه: فراتر از یک درخواست ساده! 🌀
تا الان در مورد سادهترین نوع اپلیکیشن LLM حرف زدیم؛ اپلیکیشنی که با یه درخواست کارش تموم میشه. درک این مدل ساده، خیلی مهمه چون نقطه شروع ماست. اما اپلیکیشنهای واقعی معمولاً خیلی پیچیدهترن. این پیچیدگی در چند بعد اصلی خودشو نشون میده:
- نیاز به حافظه و وضعیت (State) بیشتر
- نیاز به اطلاعات خارجی (External Context) بیشتر
- نیاز به استدلال پیچیدهتر
- نیاز به تعامل پیچیدهتر با دنیای خارج
۱. نگهداری حافظه و وضعیت برنامه (State)
اپلیکیشن ساده ما هیچ حافظه بلندمدتی نداشت. هر درخواست یه دنیای جدید بود و اپلیکیشن هیچ خاطرهای از تعامل قبلی نداشت (مثل تکمیل کد در Copilot). اما اپلیکیشنهای پیچیدهتر معمولاً به حافظه نیاز دارن.
سادهترین مثال، یه چتباته. چتبات باید تاریخچه گفتگو رو یادش بمونه. وقتی شما یه پیام جدید میفرستید، اپلیکیشن میره تاریخچه مکالمه رو از دیتابیس میخونه و از اون به عنوان اطلاعات زمینهای برای پرامپت جدید استفاده میکنه.
اگه مکالمه خیلی طولانی بشه و تو پنجره زمینه جا نشه، دوتا راه حل داریم: یا بخشهای قدیمیتر مکالمه رو حذف کنیم (که ممکنه اطلاعات مهمی از دست بره)، یا اینکه از مدل بخوایم که بخشهای قدیمی رو برامون خلاصهسازی کنه.
۲. استفاده از اطلاعات خارجی (RAG)
حتی بهترین LLMها هم همه چیز رو نمیدونن! اونا فقط روی دادههای عمومی اینترنت آموزش دیدهان و از اتفاقات جدید یا اطلاعات خصوصی شرکت شما هیچ خبری ندارن. اگه ازشون در مورد چیزی بپرسید که نمیدونن، در بهترین حالت عذرخواهی میکنن، و در بدترین حالت، با اعتماد به نفس کامل شروع به توهم زدن (Hallucination) و گفتن اطلاعات غلط میکنن.
برای حل این مشکل، از یه تکنیک فوقالعاده مهم به اسم RAG (Retrieval Augmented Generation) استفاده میکنیم. منطق RAG اینه: ما پرامپت رو با اطلاعاتی که از منابع خارجی (و غیرقابل دسترس برای مدل) به دست میاریم، «تقویت» میکنیم.
این منابع خارجی میتونن هر چیزی باشن: مستندات داخلی شرکت شما، سوابق پزشکی کاربر، یا اخبار روز.
چطور اطلاعات خارجی رو پیدا کنیم؟
ما این اطلاعات رو در یه نوع موتور جستجوی خاص (مثل Elasticsearch یا پایگاه دادههای برداری مثل Pinecone) ذخیره میکنیم. بعد موقع نیاز، از یکی از این روشها برای جستجو استفاده میکنیم:
- روش ساده: عیناً درخواست کاربر رو به عنوان عبارت جستجو به موتور جستجو میفرستیم.
- روش هوشمندانه: از خودِ LLM میپرسیم: «به نظرت بهترین عبارت جستجو برای پیدا کردن جواب این کاربر چیه؟» و بعد از جواب مدل برای جستجو استفاده میکنیم.
- روش پیشرفته (ابزارها): یه ابزار «جستجو» در اختیار دستیار هوش مصنوعی قرار میدیم و بهش اجازه میدیم خودش تصمیم بگیره که «کِی» و «با چه عبارتی» جستجو رو انجام بده.
۳. افزایش عمق استدلال: زنجیره تفکر (Chain-of-Thought)
یکی از چیزهای شگفتانگیز در مورد LLMهای جدید این بود که شروع به استدلال کردن کردن! مثلاً اگه به GPT-2 یه متن میدادید و آخرش مینوشتید `TL;DR` (مخفف Too Long; Didn't Read)، مدل میفهمید که باید متن رو خلاصه کنه!
در سالهای اخیر، ما یاد گرفتیم که چطور مدلها رو به استدلالهای پیچیدهتر وادار کنیم. یکی از سادهترین و در عین حال قدرتمندترین تکنیکها، «زنجیره تفکر» (Chain-of-Thought Prompting) نام داره.
منطقش خیلی جالبه: برخلاف ما آدما، LLMها مونولوگ داخلی ندارن. یعنی نمیتونن قبل از جواب دادن، تو ذهنشون با خودشون حرف بزنن و فکر کنن. اونا فقط به صورت مکانیکی، توکن بعدی رو بر اساس توکنهای قبلی تولید میکنن.
پس اگه میخوایم مدل قبل از جواب دادن «فکر کنه»، باید مجبورش کنیم که با صدای بلند فکر کنه! یعنی ازش بخوایم که مراحل فکر کردن و استدلالش رو قدم به قدم تو خروجی بنویسه و بعد جواب نهایی رو بده. این کار باعث میشه که جواب نهایی مدل، با فرآیند فکری خودش سازگار باشه و در نتیجه، خیلی دقیقتر و منطقیتر بشه.
مثال زنجیره تفکر:
❌ پرامپت بد: «اگه ۵ تا سیب داشته باشم و ۲ تاشو بخورم، بعد دوستم ۳ تا سیب بهم بده، چندتا سیب دارم؟»
✅ پرامپت خوب (با زنجیره تفکر): «اگه ۵ تا سیب داشته باشم و ۲ تاشو بخورم، بعد دوستم ۳ تا سیب بهم بده، چندتا سیب دارم؟ مرحله به مرحله توضیح بده چطور به جواب میرسی.»
در حالت دوم، مدل اول توضیح میده (۵ - ۲ = ۳، بعد ۳ + ۳ = ۶) و بعد جواب نهایی (۶) رو میده، که احتمال درست بودنش خیلی بیشتره.
۴. تعامل با دنیای خارج: استفاده از ابزارها (Tool Usage) 🛠️
LLMها به تنهایی در یک دنیای بسته زندگی میکنن. اونا از دنیای خارج (مثلاً وضعیت آب و هوای الان یا قیمت بلیط هواپیما) خبر ندارن و نمیتونن هیچ تغییری در دنیای واقعی ایجاد کنن. این یه محدودیت بزرگه. برای حل این مشکل، مدلهای جدید یاد گرفتن که از «ابزارها» (Tools) استفاده کنن.
منطقش خیلی ساده است: شما تو پرامپت، یه سری ابزار (که در واقع توابع برنامهنویسی هستن) رو به مدل معرفی میکنید و بهش میگید هر کدوم چیکار میکنن. بعد، مدل در طول مکالمه، اگه لازم دید، میتونه درخواست اجرای یکی از این ابزارها رو با پارامترهای مناسب بده.
البته مدل خودش نمیتونه کد اجرا کنه! اپلیکیشن شما این درخواست رو میگیره، تابع واقعی رو در دنیای واقعی اجرا میکنه، نتیجهاش رو میگیره و دوباره به عنوان اطلاعات جدید به مکالمه اضافه میکنه تا مدل بتونه از اون اطلاعات برای ادامه استدلالش استفاده کنه.
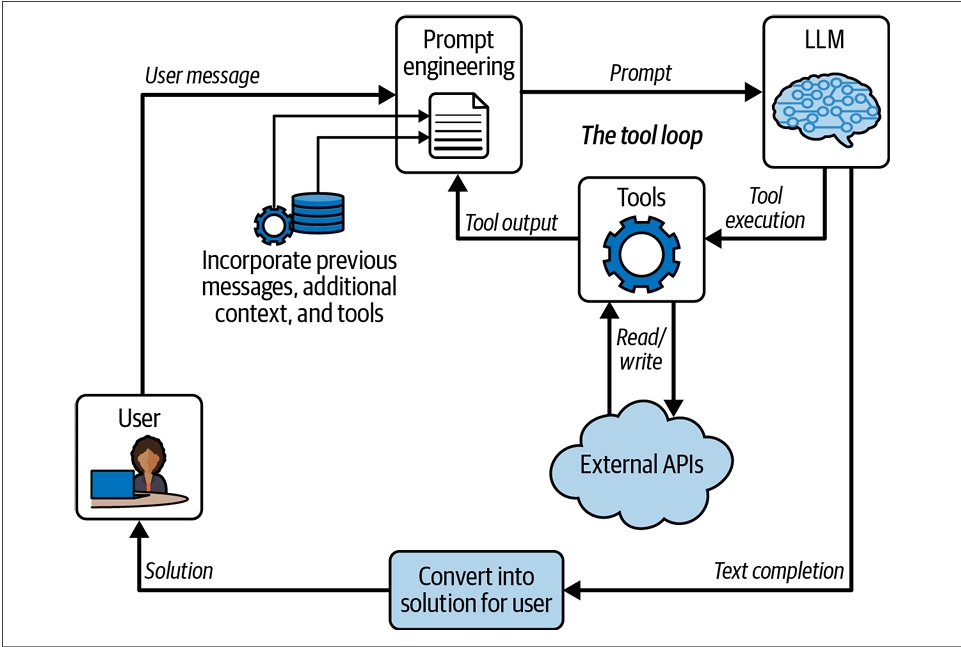
از خواندن تا نوشتن!
ابزارها میتونن فقط برای «خواندن» اطلاعات باشن (مثل جستجو در ویکیپدیا یا چک کردن ایمیلهای جدید). اما جایی که قضیه واقعاً هیجانانگیز میشه، وقتیه که به مدل اجازه میدیم با ابزارهاش در دنیای واقعی «تغییر» ایجاد کنه!
با این قابلیت، میشه دستیارهایی ساخت که کد مینویسن و پول ریکوئست ایجاد میکنن، برامون بلیط هواپیما و هتل رزرو میکنن و کلی کارهای شگفتانگیز دیگه. البته قدرت زیاد، مسئولیت زیادی هم میاره! چون مدلها همیشه ممکنه اشتباه کنن، نباید بهشون اجازه بدیم بدون تایید نهایی ما، یه سفر به یونان رزرو کنن، فقط چون ما یه بار گفتیم دلمون میخواد یه روزی بریم اونجا!
ارزیابی کیفیت اپلیکیشن LLM: از کجا بفهمیم کارمون درسته؟ 🤔
یادتونه گفتیم LLMها همیشه ممکنه اشتباه کنن؟ دقیقاً به همین خاطر، وقتی داریم یه اپلیکیشن LLM میسازیم، باید دائماً کیفیت کارمون رو ارزیابی کنیم. قبل از اینکه یه قابلیت جدید رو منتشر کنید، حتماً براش نمونه اولیه بسازید و یه سری معیارهای کمی جمعآوری کنید تا ببینید مدل چطور رفتار میکنه. بعد از انتشار هم، باید دادههای تلهمتری (Telemetry) رو ثبت کنید تا حواستون به رفتار مدل و کاربر باشه و اگه کیفیت افت کرد، سریع متوجه بشید.
ما دو نوع ارزیابی اصلی داریم:
۱. ارزیابی آفلاین (قبل از انتشار) 🧪
ارزیابی آفلاین یعنی تست کردن ایدههای جدید، قبل از اینکه کاربرهای واقعی رو در معرض یه تجربه تست نشده قرار بدیم. اینجا چون مشتری واقعی نداریم که بهمون بگه کارمون خوبه یا بد، باید خودمون یه راهی برای شبیهسازی این ارزیابی پیدا کنیم.
گاهی وقتا شانس با ما یاره! مثلاً برای تکمیل کد در Copilot، یه معیار خوب برای رضایت کاربر اینه که آیا کدی که تولید میشه، کار میکنه یا نه. این رو میشه به راحتی تست کرد! ما دقیقاً همین کار رو میکردیم: یه تیکه از یه کد سالم رو حذف میکردیم، از Copilot میخواستیم کاملش کنه و بعد میدیدیم که آیا تستهای اون کد هنوز هم پاس میشن یا نه.
اما اغلب وقتا ما اینقدر خوششانس نیستیم. چطور میشه کیفیت یه دستیار برنامهریزی جلسات یا یه چتبات عمومی رو ارزیابی کرد؟ یه رویکرد جدید اینه که از یه LLM دیگه به عنوان داور استفاده کنیم! یعنی از یه مدل دیگه بخوایم که مکالمهها رو بخونه و بگه کدوم نسخه بهتر بوده.
نکته مهم: موقع ارزیابی آفلاین، سعی کنید تا جای ممکن کل اپلیکیشن رو تست کنید، نه فقط یه بخشش رو. اگه مرحله جمعآوری اطلاعات زمینهای رو نادیده بگیرید، ممکنه موقع انتشار با یه سورپرایز خیلی بد روبرو بشید!
۲. ارزیابی آنلاین (بعد از انتشار) 📈
در ارزیابی آنلاین، ما دنبال بازخورد کاربرهای واقعی هستیم. البته این بازخورد حتماً نباید پر کردن فرمهای طولانی باشه. شاهرگ حیاتی ارزیابی آنلاین، دادههای تلهمتری هست. پس همه چیز رو اندازه بگیرید!
- بازخورد مستقیم: سادهترین راه، پرسیدن مستقیم از کاربره. همون دکمههای لایک 👍 و دیسلایک 👎 که کنار جوابهای ChatGPT میبینید. البته این روش یه مشکلی داره: معمولاً فقط کاربرهای خیلی عصبانی رأی میدن (و همیشه منفی!)، پس دادهها ممکنه یه کم سوگیرانه باشن.
- شاخصهای غیرمستقیم: اینجا باید خلاق باشیم! مثلاً برای تکمیل کد در Copilot، ما اندازه میگیریم که کاربرها چند درصد از پیشنهادها رو قبول میکنن و آیا بعد از قبول کردن، دوباره برمیگردن و کد رو ویرایش میکنن یا نه. شما هم باید برای اپلیکیشن خودتون، شاخصهای غیرمستقیم خلاقانهای پیدا کنید.
چیزی رو اندازه بگیرید که مهمه!
دنبال معیاری باشید که واقعاً نشوندهنده افزایش بهرهوری برای مشتری شما باشه. مثلاً برای یه دستیار برنامهریزی جلسات، به جای اینکه «مدت زمان جلسه» رو اندازه بگیرید (که میتونه هم خوب باشه هم بد)، «تعداد جلساتی که با موفقیت ساخته شدن» رو اندازه بگیرید.
جمعبندی فصل 🏁
تو این فصل، یاد گرفتیم که یه اپلیکیشن LLM در واقع یه لایه مترجم بین دنیای مشکل کاربر و دنیای متنی مدله. روی نیمه اول حلقه (مسیر پیشرو) زوم کردیم و دیدیم که چطور پرامپت با جمعآوری اطلاعات زمینهای، استخراج مهمترین بخشها و سر هم کردن اونها ساخته میشه. بعد هم دیدیم که مهندسی پرامپت چقدر میتونه با نیاز به حافظه، اطلاعات خارجی، استدلال پیچیده و ابزارهای خارجی، پیچیده بشه.
تو این فصل، به تمام موضوعات مربوط به ساخت اپلیکیشن LLM یه ناخنک زدیم. در فصلهای بعدی، قراره به صورت عمیق وارد هر کدوم از این موضوعات بشیم و یاد بگیریم چطور اپلیکیشنهای پیشرفتهتری بسازیم.






