
فصل دوم: کالبدشکافی مغز LLMها! 🧠
ما تو مقاله اولیه سایت تاریخچه CHATGPT رو بررسی کردیم و اما پس دلتون میخواد بشید اون استاد نجوا با غول هوش مصنوعی که با چندتا پرامپت هوشمندانه، گنج دانش و قدرت پردازشش رو آزاد میکنه؟ عالیه! اما برای اینکه بفهمید چه پرامپتی «هوشمندانه» است و چطور باید جواب درست رو از دل این مدلها بیرون بکشید، اول باید بفهمید که اینا اصلاً چطوری اطلاعات رو پردازش میکنن؛ یا به عبارتی، چطوری فکر میکنن.
تو این فصل، قراره مثل باز کردن یه پیاز، لایه به لایه به دل ماجرا نفوذ کنیم. اول از بیرونیترین لایه شروع میکنیم و بعد ذره ذره عمیقتر میشیم.
نقشه راه ما تو این فصل (روش پیازی! 🧅):
- 🎯 LLMها چی هستن؟ میبینیم که این مدلها در واقع طوطیهای مقلد فوقالعاده حرفهای متن هستن.
- 👁️ LLMها دنیا رو چطور میبینن؟ یاد میگیریم که چطور متن رو به تکههای کوچیک به اسم «توکن» تقسیم میکنن و اگه نتونن این کارو خوب انجام بدن چه اتفاقی میافته.
- 🧱 دونه به دونه: میفهمیم که چطور این توکنها رو پشت سر هم و کلمه به کلمه تولید میکنن.
- 🌡️ دما و احتمالات: با روشهای مختلف انتخاب کلمه بعدی آشنا میشیم.
- 🧠 معماری ترنسفورمر: به داخلیترین لایه مغز LLM میریم و میبینیم که از کلی «مغز کوچولو» تشکیل شده که با یه بازی پرسش و پاسخ به اسم «توجه» (Attention) با هم حرف میزنن و این چه ربطی به ترتیب نوشتن پرامپتهای ما داره.
یه نکته مهم قبل از شیرجه زدن! 🏊♂️
یادتون باشه که این کتاب در مورد استفاده کردن از LLMهاست، نه ساختن اونها. پس کلی جزئیات فنی باحال هست که ما بهشون اشاره نمیکنیم چون برای مهندسی پرامپت لازم نیستن. اگه دنبال فرمولهای ریاضی و ضرب ماتریس هستید، باید سراغ منابع دیگه برید (مقاله کلاسیک The Illustrated Transformer یه نقطه شروع عالی برای این کاره).
اما بهتون قول میدیم برای نوشتن پرامپتهای فوقالعاده، به اون حد از جزئیات فنی نیاز ندارید.
LLMها واقعاً چی هستن؟ (سادهترین تعریف ممکن)
تو پایهایترین سطح، یک LLM یه سرویسه که یه متن از شما میگیره و یه متن به شما تحویل میده: متن ورودی، متن خروجی. به ورودی میگن پرامپت (Prompt) و به خروجی میگن تکمیل (Completion) یا گاهی وقتا پاسخ (Response). به همین سادگی!
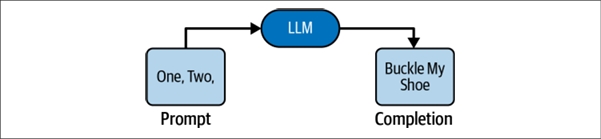
وقتی یه LLM برای اولین بار به دنیا میاد و هنوز هیچی یاد نگرفته (آموزش ندیده)، خروجیهاش یه مشت حروف و علائم درهم و برهم و بیربطه. مثل یه نوزاد که فقط صداهای نامفهوم تولید میکنه. باید اول آموزش ببینه تا به درد بخور بشه. بعد از آموزش، دیگه فقط به متن با متن جواب نمیده، بلکه به زبان با زبان پاسخ میده.
آموزش دادن این مدلها کلی مهارت، کامپیوترهای خفن و زمان لازم داره که از عهده اکثر تیمهای برنامهنویسی خارجه. به خاطر همین، اکثر اپلیکیشنها از مدلهای آماده و همهکاره استفاده میکنن که بهشون میگن «مدلهای پایه» (Foundation Models). پس ما از شما انتظار نداریم که خودتون یه LLM آموزش بدید، اما اگه میخواید ازشون استفاده کنید (مخصوصاً تو برنامهنویسی)، خیلی مهمه که بفهمید این مدلها برای انجام چه کاری آموزش دیدهاند.
💡 «تنظیم دقیق» یا Fine-Tuning یعنی چی؟
آموزش LLMها خیلی پرهزینهست، در حالی که خیلی از درسهای پایه (مثل گرامر زبان فارسی) تو همه دیتاستها یکسانه. برای همین، معمولاً به جای اینکه یه مدل رو از صفر شروع کنن، یه کپی از یه مدل از قبل آموزشدیده رو برمیدارن و اون رو با دادههای جدید، برای یه کار تخصصیتر «تنظیم دقیق» میکنن.
مثال: مدل OpenAI Codex (که برای کدنویسی ساخته شده) در واقع یه کپی از مدل GPT-3 (که برای زبان عادی بود) هست که اون رو با کلی کد منبع باز از سایت گیتهاب، تنظیم دقیق کردن تا کدنویس ماهری بشه. 👨💻
نکته مهم برای پرامپتنویسی: اگه مدلی روی داده A آموزش دیده و بعد روی داده B تنظیم دقیق شده، شما باید پرامپتهاتون رو طوری بنویسید که انگار مدل فقط روی داده B آموزش دیده.
هدف اصلی از آموزش: تقلید کردن! 🦜
LLMها با استفاده از یه مجموعه خیلی بزرگ از اسناد و متون (که بهش میگن «مجموعه آموزشی» یا Training Set) آموزش میبینن. این مجموعه آموزشی ترکیبی از همه چیزه: کتابها، مقالهها، مکالمههای ردیت، کدهای گیتهاب و... .
از مدل انتظار میره که یاد بگیره خروجیهایی تولید کنه که دقیقاً شبیه به متنهای مجموعه آموزشی باشن. به عبارت دیگه، وقتی شما شروع یه متن از مجموعه آموزشی رو به عنوان پرامپت به مدل میدید، بهترین خروجی از نظر مدل، ادامهایه که به احتمال زیاد در سند اصلی اومده. پس یادتون باشه:
مدلهای زبان، استادان تقلید هستند!
تفاوت اصلی LLM با یه موتور جستجوی خفن چیه؟ 🧐
خب، پس فرق یه LLM با یه موتور جستجوی گنده مثل گوگل چیه؟ بالاخره موتور جستجو هم اگه بهش اول یه متن رو بدی، میتونه با دقت ۱۰۰٪ ادامهاش رو تو کل اینترنت پیدا کنه و بهت بده. پس چرا این همه هیاهو برای LLMهاست؟
اینجا تفاوت کلیدی مشخص میشه: هدف ما این نیست که یه طوطی سخنگو داشته باشیم که فقط متنها رو از حفظ تکرار کنه. LLM نباید متنها رو از بَر کنه، بلکه باید الگوهای درون اون متنها (مخصوصاً الگوهای منطقی و استدلالی) رو یاد بگیره و بتونه اونها رو روی هر پرامپت جدیدی پیاده کنه، نه فقط اونایی که تو آموزشش دیده. صرفاً از حفظ کردن، یک ایراد بزرگ محسوب میشه!
وقتی مدل به جای یادگیری، حفظ میکنه! (Overfitting)
البته بعضی وقتا این پیشگیری شکست میخوره و مدل به جای یاد گرفتن الگوها، یه تیکههایی از متن رو کاملاً از حفظ میکنه. به این ایراد میگن «بیشبرازش» یا Overfitting.
این اتفاق تو مدلهای تجاری بزرگ نادره، اما خوبه که حواستون بهش باشه. یعنی اگه دیدید یه LLM یه مسئلهای که قبلاً تو آموزشش دیده رو به راحتی حل کرد، لزوماً به این معنی نیست که اگه یه مسئله شبیه به همون ولی جدید بهش بدید، بتونه به همون خوبی حلش کنه. شاید فقط داره جواب حفظ شده رو طوطیوار تکرار میکنه!
💡 طرز فکر درست برای مهندسی پرامپت
بعد از اینکه یه مدت با LLMها کار کنید، کم کم یه حس ششم پیدا میکنید که مدل چطور رفتار میکنه. برای اینکه این حس ششم رو تقویت کنید، این طرز فکر رو تمرین کنید:
وقتی میخواید بدونید یه پرامپت چطور کامل میشه، از خودتون نپرسید که «یه آدم منطقی به این چی جواب میده؟».
به جاش از خودتون این سوال کلیدی رو بپرسید:
«اگه یه متن رو به صورت تصادفی از کل اینترنت (مجموعه آموزشی) انتخاب میکردم که با همین پرامپت من شروع شده بود، به احتمال زیاد ادامه اون متن چی میتونست باشه؟»
جوابی که LLM به شما میده، همین «ادامه محتمل» هست.
🧠 LLM چطور ادامه یه داستان رو حدس میزنه؟ (یه مثال عملی باحال!) 💡
بریم سراغ یه مثال که قشنگ دستتون بیاد مدل چطوری فکر میکنه. این متن رو در نظر بگیرید:
«دیروز تلویزیونم خراب شد. الان نمیتونم روشنش کنم اصلاً»
برای متنی که اینطوری شروع میشه، به نظر شما از نظر آماری، محتملترین کلمه بعدی چیه؟
- غ۲ی۳ط۴و
- پنجشنبه.
- . (نقطه)
هیچکدوم از اینا غیرممکن نیستن. شاید یه گربه از رو کیبورد رد شده باشه 🐈 و گزینه ۱ تولید بشه، یا شاید جمله موقع ویرایش قاطی شده باشه و گزینه ۲ بیاد. ولی خداییش، محتملترین ادامه، گزینه ۳ (یعنی گذاشتن نقطه و تمام کردن جمله) هست. تقریباً همه LLMها هم همین گزینه رو انتخاب میکنن.
حالا قضیه رو یه کم پیچیدهتر کنیم... 🤔
خب، فرض کنیم مدل جمله رو تموم کرد. حالا پرامپت ما اینه:
«دیروز تلویزیونم خراب شد. الان نمیتونم روشنش کنم اصلاً.»
به نظرتون محتملترین ادامه برای این متن چیه؟
- الف) 📚 برای همین امشب تصمیم گرفتم بشینم کتاب بخونم.
- ب) ⚽ پس بهتره بازی رو خونه شما ببینیم؟
- ج) 🛠️
اول سعی کنید تلویزیون رو از برق بکشید و دوباره به برق بزنید.
خب، اینجا داستان جالب میشه! جواب کاملاً بستگی به «مجموعه آموزشی» مدل داره.
- سناریو ۱: اگه مدل فقط کتاب داستان و رمان خونده باشه، احتمالاً گزینه «الف» رو انتخاب میکنه چون خیلی شبیه به ادامه یه داستانه.
- سناریو ۲: اگه مدل کلی ایمیل و چت هم خونده باشه، یهو گزینه «ب» خیلی محتمل به نظر میاد چون شبیه یه مکالمه دوستانه است.
اما جواب واقعی که یه مدل واقعی (text-davinci-003) تولید کرده، گزینه «ج» هست! 🤯 چرا؟ چون این مدل با حجم عظیمی از مکالمات پشتیبانی مشتری و راهنماهای آنلاین آموزش دیده و داره رفتار اونها رو تقلید میکنه.
💡 پس نکته طلایی داستان چیه؟
یه الگو داره اینجا شکل میگیره: هر چی مجموعه آموزشی مدل رو بهتر بشناسید، بهتر میتونید رفتار و خروجی احتمالی اون مدل رو حدس بزنید.
خیلی از شرکتهای بزرگ، مجموعه آموزشیشون رو فاش نمیکنن چون این «فوت کوزهگری» و سس مخصوصشونه! 🤫 اما حتی با این وجود، معمولاً میشه یه حدس منطقی زد که این مدلها با چه نوع متنهایی آموزش دیدن (مثلاً کل اینترنت!).
🧠 مغز انسان در مقابل پردازش LLM: یه تفاوت اساسی!
گفتیم که LLM فقط محتملترین ادامه رو انتخاب میکنه. این روش با طرز فکر ما انسانها موقع نوشتن، زمین تا آسمون فرق داره. چرا؟ چون ما آدما وقتی مینویسیم، کارهای دیگهای هم انجام میدیم.
فرض کنید میخواید یه پست وبلاگ در مورد یه پادکست باحال بنویسید. شروع میکنید به نوشتن:
«تو آخرین قسمت از پادکست "بقیه تاریخ"، در مورد جنگهای صد ساله صحبت میکنن (لینک پادکست: http://»
شما که لینک رو از حفظ نیستید! اینجا نوشتن رو متوقف میکنید، یه تب جدید باز میکنید، تو گوگل سرچ میکنید و لینک درست رو پیدا میکنید. 🕵️♂️ اگه پیداش نکردید، برمیگردید و متنتون رو ویرایش میکنید و مثلاً مینویسید «(متاسفانه این قسمت دیگه در دسترس نیست)».
💡 تفاوت کلیدی اینجاست: LLM فقط حدس میزنه!
مدل هوش مصنوعی نه میتونه گوگل کنه، نه میتونه متن رو ویرایش کنه. پس چیکار میکنه؟ فقط حدس میزنه! 🤷♂️
مدل هیچوقت شک و تردید خودش رو بروز نمیده. نمیگه «مطمئن نیستم» یا «این فقط یه حدسه». چرا؟ چون کل کار مدل، از اول تا آخر، حدس زدنه! این حدس زدن جایی اتفاق میافته که ما آدما معمولاً روشمون رو عوض میکنیم (یعنی به جای نوشتن، میریم سراغ تحقیق و جستجو).
استاد جعلهای باورپذیر! 🎭
LLMها در تقلید کردن از الگوهایی که دیدن، فوقالعادهان! اگه ازشون یه کد ملی الکی بخوان، یه رشته عدد کاملاً شبیه به کد ملی واقعی بهتون میدن. اگه یه لینک پادکست بخوان، یه آدرس اینترنتی کاملاً شبیه به لینک واقعی براتون میسازن!
مثلاً من از یکی از مدلهای GPT-3 خواستم که همون لینک پادکست رو کامل کنه و این جواب رو بهم داد:
http://www.acast.com/the-rest-is-history-episode-5-the-Hundred-Years-War-1411-1453-with-dr-martin-kemp)
حالا بیاید این جواب رو کالبدشکافی کنیم:
- آدرس URL کاملاً واقعی به نظر میرسه، ولی کاملاً ساختگیه!
- دکتر مارتین کمپ کیه؟ آیا اصلاً همچین شخصی وجود داره؟ بله! یه مورخ هنر به این اسم تو آکسفورد هست. اما آیا تو این پادکست در مورد جنگهای صد ساله حرف زده؟ نه!
اینجا مدل، الگوهای مختلفی که دیده (ساختار URL، ترکیب اسم و فامیل انگلیسی، اسم پادکست) رو با هم قاطی کرده و یه جواب کاملاً باورپذیر ولی غلط ساخته. به این پدیده میگن «توهم» یا Hallucination که در ادامه بیشتر در موردش صحبت میکنیم.
😵 «توهم» یا Hallucination: وقتی هوش مصنوعی قصه میبافه!
اینکه LLMها فقط ماشینهای تقلیدکننده هستن، یه نتیجه بد هم داره: توهم (Hallucination). یعنی مدل با اعتماد به نفس کامل، اطلاعاتی رو به شما میده که کاملاً اشتباهه ولی خیلی واقعی به نظر میرسه. این یکی از بزرگترین مشکلات موقع کار با LLMهاست.
از نظر خود مدل، جوابی که توهم زده با یه جواب درست هیچ فرقی نداره. برای همین، دستورهایی مثل «الکی از خودت چیزی در نیار» فایده چندانی نداره! 😅 به جاش، راه حل بهتر اینه که از مدل بخوایم یه سری اطلاعات زمینهای بهمون بده که بشه اونها رو چک کرد. مثلاً:
- ازش بخوایم استدلالش رو توضیح بده.
- ازش منبع یا لینک بخوایم.
- جزئیات و کلمات کلیدی بهمون بده که بتونیم خودمون سرچ کنیم.
مثلاً چک کردن جمله «یه پادشاه انگلیسی بود که با دخترعموش ازدواج کرد» خیلی سخته. اما چک کردن این جمله «یه پادشاه انگلیسی بود که با دخترعموش ازدواج کرد، یعنی جورج چهارم که با کارولین برانشوایگ ازدواج کرد» خیلی راحتتره. بهترین راه برای مقابله با توهم اینه: «اعتماد کن، ولی بررسی کن»، البته اون قسمت اعتمادش رو هم حذف کنید! 😉
سوگیری حقیقت: وقتی مدل هر چی بگی باور میکنه!
شما میتونید خودتون هم باعث توهم زدن مدل بشید! اگه تو پرامپتتون به چیزی اشاره کنید که وجود خارجی نداره، مدل معمولاً فرض میکنه که اون چیز واقعیه و بر همون اساس جواب میده. به این میگن «سوگیری حقیقت» (Truth Bias).
چطور از این سوگیری به نفع خودمون استفاده کنیم؟ 💡
اگه میخواید مدل یه سناریوی فرضی یا تخیلی رو بررسی کنه، لازم نیست بهش بگید «فرض کن که...». فقط کافیه اون سناریو رو به عنوان یه حقیقت بیان کنید!
❌ نگویید: «فرض کن الان سال ۲۰۳۰ هست و نئاندرتالها دوباره زنده شدن.»
✅ بگویید: «الان سال ۲۰۳۱ هست، یعنی یک سال کامل از زمانی که اولین نئاندرتالها دوباره زنده شدن میگذره.»
مدل با این روش، خیلی راحتتر وارد دنیای خیالی شما میشه و به سوالاتتون جواب میده.
اما این سوگیری حقیقت میتونه خطرناک هم باشه، مخصوصاً وقتی دارید یه اپلیکیشن میسازید. خیلی راحت ممکنه موقع ساختن پرامپت به صورت خودکار، یه اطلاعات غلط یا بیمعنی وارد پرامپت بشه. یه آدم اگه این پرامپت رو بخونه، با تعجب بهتون نگاه میکنه و میگه «جداً؟!» 🤨 اما LLM این گزینه رو نداره. اون تمام تلاشش رو میکنه که فرض کنه پرامپت شما واقعیه و بعیده که اشتباهتون رو اصلاح کنه.
پس یادتون باشه: شما مسئولید که به مدل یه پرامپت درست و حسابی بدید که نیازی به اصلاح نداشته باشه!
👁️ چشمهای هوش مصنوعی: LLMها دنیا رو چطوری میبینن؟ (توکنها!)
گفتیم که LLMها متن رو میگیرن و متن تحویل میدن. اما بیاید یه کم عمیق تر بشیم و ببینیم این مدلها اصلاً چطوری متن رو «میبینن»؟ ما عادت کردیم که متن رو دنبالهای از حروف ببینیم، اما LLMها اینطوری نیستن! اونها میتونن در مورد حروف استدلال کنن، اما این قابلیت ذاتیشون نیست و نیاز به تمرکز خیلی زیادی از طرف مدل داره. (همین الان که این متن نوشته میشه، حتی خفنترین مدلها هم با سوالی مثل «کلمه "توتفرنگی" چندتا "ت" داره؟» به چالش کشیده میشن!)
باور کنید یا نه، ما هم حرف به حرف نمیخونیم! 🧠
شاید جالب باشه بدونید که ما آدمها هم واقعاً حرف به حرف نمیخونیم! تو مراحل اولیه پردازش مغز ما، حروف به سرعت به «کلمه» تبدیل میشن. چیزی که ما میخونیم کلمهها هستن، نه حروف. به خاطر همینه که خیلی وقتا غلطهای املایی رو نمیبینیم و از روشون رد میشیم؛ چون مغز ما قبل از اینکه به بخش خودآگاهمون برسه، اونها رو اصلاح کرده! 😉
میشه با جملههایی که عمداً به هم ریخته شدن کلی سرگرم شد (تصویر چپ). اما اگه متن رو طوری به هم بریزید که مرز بین کلمهها از بین بره، خوانندههاتون روزگارشون سیاه میشه! (تصویر راست).
مثال متن به هم ریخته:
✅ حالت خوانا: «بر اساس تقیقحات یک دانشمند در دانشاگه کمبریج...» (حروف داخل کلمات جابجا شدن)
❌ حالت ناخوانا: «براساستیقحاتیکدانشمندردانشاگ هکمبریج...» (مرز کلمات حذف شده)
اکثر آدما حالت اول رو خیلی راحتتر میخونن!
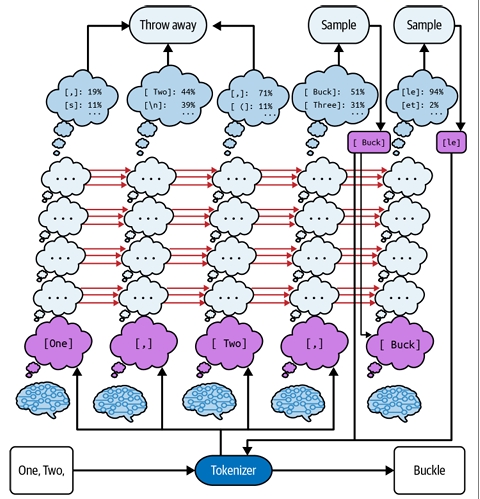
معرفی میکنم: «توکن»، الفبای دنیای LLMها!
درست مثل ما آدمها، LLMها هم حروف رو تکی تکی نمیخونن. وقتی شما یه متن رو برای مدل میفرستید، اون متن اول از همه به یه سری تکههای چند حرفی به اسم «توکن» (Token) شکسته میشه. این توکنها معمولاً ۳-۴ تا حرف طول دارن، ولی برای کلمههای خیلی رایج، توکنهای بلندتری هم وجود داره. به کل توکنهایی که یه مدل بلده، میگن «واژگان» (Vocabulary) اون مدل.
سفر یک پرامپت از دست شما تا جواب نهایی 🚀
- شما یه متن مینویسید: «هوا چطوره؟»
- توکنایزر (Tokenizer): این دستگاه متن شما رو به تکههای کوچیک (توکن) میشکنه. مثلاً: ["هوا", " ", "چطوره", "؟"]
- تبدیل به اعداد: هر توکن به یه عدد مخصوص در دیکشنری مدل تبدیل میشه. مثلاً: [101, 3, 202, 5]
- پردازش در مغز LLM: مدل این اعداد رو پردازش میکنه و یه دنباله عدد جدید به عنوان جواب تولید میکنه.
- بازگشت به توکن: اعداد جواب دوباره به توکن تبدیل میشن. مثلاً: ["هوا", " ", "آفتابیه", "."]
- بازگشت به متن: توکنها به هم میچسبن و جواب نهایی که شما میبینید ساخته میشه: «هوا آفتابیه.»
پس LLMها متن رو به صورت دنبالهای از توکنها میبینن، و ما آدمها به صورت دنبالهای از کلمات. این باعث میشه به نظر بیاد که دیدگاهمون خیلی شبیهه، اما چندتا تفاوت خیلی خیلی مهم و حیاتی وجود داره که در ادامه بهشون میپردازیم.
🧐 تفاوتهای کلیدی بین دید ما و دید LLM
گفتیم که هم ما و هم LLMها متن رو به صورت تکههای کوچیکتر میبینیم (ما کلمه، اونها توکن). اما این شباهت خیلی سطحیه و چندتا تفاوت حیاتی وجود داره:
تفاوت شماره ۱: توکنایزر LLMها رباتیک و دقیق عمل میکنه!
ما آدما وقتی یه کلمه با غلط املایی میبینیم، مغزمون به صورت «فازی» و حدودی سعی میکنه شبیهترین کلمه درست رو پیدا کنه. اما توکنایزر LLMها کاملاً قطعی و رباتیک عمل میکنه. این باعث میشه غلطهای املایی مثل یه جوش بزرگ روی صورت، خیلی تابلو بشن!
مثلاً کلمه "ghost" تو واژگان مدلهای GPT یه توکن واحده. اما اگه به اشتباه تایپ کنید "gohst"، توکنایزر اون رو به سه تا توکن جدا میشکنه: [g] [oh] [st]. این دنباله کاملاً با توکن اصلی فرق داره و برای مدل خیلی واضحه که یه جای کار میلنگه. (البته LLMها انقدر غلط املایی تو آموزششون دیدن که معمولاً در مقابلش مقاوم هستن و کارشون راه میفته!)
تفاوت شماره ۲: LLMها نمیتونن روی حروف زوم کنن! 🔬
ما آدما میتونیم سرعتمون رو کم کنیم و آگاهانه حروف یه کلمه رو دونه دونه بررسی کنیم. اما LLM فقط همون توکنایزر داخلی خودش رو داره و نمیتونه این کار رو بکنه. این باعث میشه کارهایی که نیاز به شکستن و دوباره سر هم کردن توکنها دارن، برای مدل خیلی خیلی سخت بشن.
یه مثال عالی، برعکس کردن حروف یه کلمهست. این کار برای ما یه بازی ساده است، اما برای LLMها یه کابوسه! چون باید توکنها رو بشکنن، حروف رو جابجا کنن و دوباره توکن بسازن. نتیجه معمولاً یه فاجعه خندهداره!
شما: کلمه "دانشگاه" رو برعکس کن.
ChatGPT (احتمالاً): هاگشناد... نه ببخشید... هاگش ناد... وایسا... هگشناد!
💡 نکته طلایی برای شما به عنوان برنامهنویس
اگه کاری که میخواید مدل انجام بده، شامل شکستن و سر هم کردن توکنهاست (مثل پیدا کردن کلماتی که با "Sw" شروع میشن)، سعی کنید این بخش از کار رو خودتون در پیشپردازش یا پسپردازش انجام بدید و بار رو از روی دوش مدل بردارید.
مثلاً برای پیدا کردن «کشور اروپایی که با Sw شروع میشه»، اول از LLM بخواید یه لیست بلند بالا از «تمام کشورهای اروپایی» بهتون بده. بعد خودتون با یه کد ساده، اونهایی که با Sw شروع میشن رو از لیست فیلتر کنید. اگه کل کار رو به LLM بسپارید، احتمالاً جوابهای عجیب و غریب و اشتباهی مثل «سومالی» هم تو لیستش پیدا میکنید! 😅
تفاوت شماره ۳: LLMها متن رو «نمیبینن»!
آخرین تفاوت مهم اینه که ما آدما درک شهودی از خیلی جنبههای متن داریم. ما حروف رو میبینیم، برای همین میدونیم کدوم حروف گردن و کدوم صاف. ما هنر اسکی (ASCII art) رو میفهمیم چون شکلش رو میبینیم. برای ما، حرف "á" فقط یه شکل دیگه از "a" هست و موقع خوندن، مغزمون به راحتی ازش عبور میکنه.
اما برای مدل، پردازش این موارد نیاز به صرف انرژی و قدرت پردازش زیادی داره و این انرژی رو از کار اصلی که شما ازش خواستید، کم میکنه.
یه مثال خیلی مهم: حروف بزرگ و کوچک (Capitalization)
این یکی خیلی جالبه. چرا گاهی وقتا کارهای سادهای مثل بزرگ کردن تمام حروف یه متن، برای یه مدل کوچیک انقدر سخت میشه؟ حدس خودتون رو بزنید و بعد ادامه رو بخونید.
شما: جمله "strange new worlds" رو با حروف بزرگ بنویس.
مدل کوچیک (شاید): STRANGE NEW WORLDS... نه ببخشید... STR ANGE NEW WOR L DS
برای ما، A بزرگ فقط یه شکل دیگه از a کوچیکه. اما برای مدل، توکنهایی که حرف بزرگ دارن، کاملاً با توکنهای حروف کوچک فرق دارن. مدلهای بزرگتر این تفاوتها رو بهتر یاد گرفتن، اما هنوز هم این قضیه براشون یه چالش محسوب میشه.
مثلاً در توکنایزر GPT، عبارت "strange new worlds" به چهار توکن شکسته میشه: [str][ange] [ new][ worlds].
اما وقتی همینو با حروف بزرگ مینویسیم، به شش توکن شکسته میشه: [STR] [ANGE][ NEW][ WOR][L][DS]!
میبینید؟ ساختار کاملاً به هم ریخت!
بنابراین، یه مهندس پرامپت عاقل، سعی میکنه با مجبور کردن مدل به تبدیل دائم حروف کوچک به بزرگ (و برعکس)، الکی براش بار اضافه نتراشه!
🪙 شمارش توکنها: واحد پول دنیای LLMها!
یه نکته خیلی مهم: شما نمیتونید توکنایزرها و مدلها رو با هم قاطی کنید. هر مدل، توکنایزر ثابت و مخصوص به خودش رو داره. برای همین، خیلی مهمه که توکنایزر مدلی که باهاش کار میکنید رو خوب بشناسید.
شما به عنوان یه مهندس پرامپت، احتمالاً از کتابخونههایی مثل Hugging Face یا tiktoken برای کار با توکنایزرها استفاده میکنید. اما رایجترین کاری که با توکنایزر انجام میدید، تحلیلهای پیچیده نیست. در ۹۹٪ مواقع، شما فقط یه کار ساده باهاش دارید: شمارش کردن!
چرا شمردن توکنها اینقدر مهمه؟
چون از دید مدل، «تعداد توکنها» طول متن شما رو مشخص میکنه. این طول، روی همه چیز تاثیر داره:
- زمان پردازش: مدت زمانی که مدل صرف خوندن پرامپت و تولید جواب میکنه، مستقیماً به تعداد توکنها ربط داره.
- هزینه محاسباتی: قدرت پردازشی که برای یه پیشبینی لازمه، با تعداد توکنها بالا و پایین میره. به خاطر همینه که اکثر سرویسهای ارائهدهنده مدل، هزینهها رو بر اساس تعداد توکن (چه ورودی و چه خروجی) حساب میکنن. همین الان که این متن نوشته میشه، با یک دلار میشه بین ۵۰,۰۰۰ تا ۱,۰۰۰,۰۰۰ توکن خروجی خرید!
- پنجره زمینه (Context Window): این یکی از بزرگترین محدودیتهای همه مدلهای امروزیه. پنجره زمینه یعنی حداکثر مقدار متنی که یه LLM میتونه در یک لحظه بهش رسیدگی کنه.
یه LLM نمیتونه هر متنی با هر طولی رو بگیره. متن ورودی شما (پرامپت) باید تعداد توکنهاش از اندازه پنجره زمینه کمتر باشه، و مجموع توکنهای پرامپت + جواب نهایی هم نباید از این پنجره بزرگتر بشه.
اندازه پنجره زمینه معمولاً چند هزار توکنه که روی کاغذ خیلی زیاده (چندین، دهها یا حتی صدها صفحه A4!). اما در عمل، شما همیشه وسوسه میشید که این پنجره رو تا خرخره پر کنید! 😅 برای همین باید توکنها رو بشمرید تا از این اتفاق جلوگیری کنید.
💡 یه حساب سرانگشتی برای تبدیل حروف به توکن
هیچ فرمول دقیقی برای این کار وجود نداره و همه چیز به متن و توکنایزر بستگی داره. اما به طور میانگین:
- متن انگلیسی: هر ۴ حرف، تقریباً ۱ توکن میشه.
- زبانهای دیگه (مثل فارسی): توکنایزرها بهینهسازی کمتری دارن و تعداد حروف کمتری در هر توکن جا میشه (یعنی هزینه بیشتره!).
- رشتههای عددی: هر ۲ حرف، تقریباً ۱ توکن.
- رشتههای تصادفی (مثل کلیدهای رمزنگاری): بدترین حالت! تقریباً هر ۱.۵ حرف، ۱ توکن.
- کاراکترهای نادر (مثل ایموجیها): میتونن خیلی پرهزینه باشن. مثلاً ایموجی ☺ خودش دو تا توکن حساب میشه!
یه نکته فنی: اکثر مدلها یه توکن مخصوص به اسم «پایان متن» (end-of-text) دارن. این توکن تو آموزش به انتهای هر سند اضافه میشه تا مدل یاد بگیره کی باید حرف زدنش رو تموم کنه. هر وقت مدل این توکن رو تولید کنه، تولید جواب همونجا متوقف میشه.
🧱 یک توکن در هر لحظه: راز بزرگ تولید متن!
بریم سراغ یه لایه عمیقتر از پیاز و ببینیم این مدلها دقیقاً چطور جواب میسازن. این آخرین لایه قبل از رسیدن به هسته اصلیه. برخلاف تصور ما، LLM جواب رو یکجا تولید نمیکنه. فرآیند اینطوریه:
فرآیند ساخت کلمه به کلمه 🏗️
مدل، کل پرامپت شما رو میخونه و فقط یک توکن بعدی رو حدس میزنه. همین! بعد، این توکن جدید رو به انتهای پرامپت اضافه میکنه و دوباره کل متن جدید رو میخونه تا توکن بعدی رو حدس بزنه. این کار اونقدر تکرار میشه تا در نهایت یه جمله یا پاراگراف کامل ساخته بشه.
پس در واقع، مدل همیشه داره به این سوال جواب میده: «با توجه به همه چیزهایی که تا الان گفته شده، محتملترین کلمه بعدی چیه؟»
مدلهای خود-رگرسیو (Auto-Regressive)
به این فرآیند که پیشبینیها دونه به دونه انجام میشن و هر پیشبینی به پیشبینی قبلی بستگی داره، میگن «خود-رگرسیو».
یادتونه موقع تایپ کردن با گوشی، بالای کیبورد سه تا کلمه پیشنهادی میاد؟ کار کردن با یه LLM دقیقاً مثل اینه که شما پشت سر هم روی کلمه پیشنهادی وسطی کلیک کنید! 📱
💡 یه تفاوت خیلی مهم بین ما و LLMها
این الگوی منظم و تقریباً یکنواخت (تولید یک توکن در هر مرحله)، یه تفاوت بزرگ بین ما و LLMها رو نشون میده: ما آدما ممکنه موقع نوشتن مکث کنیم، فکر کنیم، یا یه چیزی رو چک کنیم. اما مدل برای هر مرحله باید حتماً یه توکن تولید کنه. LLM وقت اضافه برای فکر کردن نداره و نمیتونه کار رو متوقف کنه.
بدون بازگشت، بدون پشیمانی! unidirectional
و وقتی که یه توکن رو تولید کرد، دیگه بهش متعهده! LLM نمیتونه برگرده عقب و توکن رو پاک کنه. همچنین هیچوقت نمیاد بگه «ببخشید، اون چیزی که قبلاً گفتم اشتباه بود»، چون تو آموزشش هیچوقت متنهایی رو ندیده که نویسنده وسط متن بیاد و اشتباهش رو به صورت صریح اصلاح کنه. (چون نویسندههای واقعی برمیگردن و اشتباه رو همونجا که اتفاق افتاده اصلاح میکنن!)
وایسا، یه لحظه... اشتباه تایپی شد... منظورم این بود که... بذارید دوباره بنویسم!
این ویژگی باعث میشه LLMها گاهی وقتا خیلی لجباز و حتی مسخره به نظر برسن؛ وقتی یه مسیر رو میرن که کاملاً مشخصه اشتباهه ولی باز هم ادامه میدن. اما معنی واقعی این رفتار برای شما به عنوان طراح اپلیکیشن اینه:
قابلیت تشخیص اشتباه و برگشت از اون، باید توسط شما در اپلیکیشن تعبیه بشه، نه توسط مدل!
😵💫 وقتی هوش مصنوعی روی یک آهنگ گیر میکنه! (الگوها و تکرارها)
یکی دیگه از مشکلات سیستمهای خود-رگرسیو اینه که میتونن تو الگوهای خودشون گیر کنن. LLMها تو پیدا کردن الگو استادن، برای همین گاهی وقتا (به صورت اتفاقی) یه الگویی رو شروع میکنن و دیگه نمیتونن ازش خارج بشن. چرا؟ چون از نظر آماری، ادامه دادن یه الگو همیشه محتملتر از شکستنشه! این منجر به جوابهای خیلی تکراری و حوصلهسربر میشه.
مثلاً فرض کنید از یه مدل قدیمیتر خواستیم چندتا دلیل برای تعریف از یه رستوران بگه. ممکنه یه همچین لیستی بهمون بده:
۱. کیفیت غذاها خوب و عالی است.
۲. فضای رستوران خوب و دلنشین است.
۳. رفتار پرسنل خوب و محترمانه است.
۴. منوی رستوران خوب و متنوع است.
۵. قیمتهای رستوران خوب و منصفانه است.
۶. موقعیت رستوران خوب و در دسترس است.
۷. نظافت رستوران خوب و ... (و این داستان تا ابد ادامه دارد!)
اینجا مدل تو چندتا الگوی تکراری گیر کرده: همه جملهها با شماره شروع میشن، همه با کلمه «خوب» شروع میشن، ساختار جملهها یکسانه و مهمتر از همه، لیست هیچوقت تموم نمیشه! چون مدل هیچوقت خسته نمیشه و ادامه دادن لیست براش همیشه محتملترین کاره.
راه حل چیه؟ یا باید این تکرارها رو شناسایی و فیلتر کنیم، یا... یه کم به خروجی چاشنی تصادف اضافه کنیم! که این ما رو میرسونه به بحث بعدی...
🌡️ دما چیه؟ دکمه خلاقیت هوش مصنوعی!
تا الان گفتیم که LLM محتملترین توکن بعدی رو انتخاب میکنه. اما اگه یه لایه دیگه از پیاز رو برداریم، میبینیم که در واقع، مدل برای تمام توکنهای ممکن یه احتمال حساب میکنه و بعد از بین اونها یکی رو انتخاب میکنه. به فرآیند انتخاب توکن نهایی میگن «نمونهبرداری» (Sampling).
یعنی مدل فقط نمیگه «محتملترین کلمه "کتاب" است». بلکه میگه: «کلمه "کتاب" با احتمال ۶۰٪، کلمه "دفتر" با احتمال ۲۰٪، کلمه "مداد" با احتمال ۵٪ و... محتملترین گزینهها هستن.»
حالا پارامتری به اسم «دما» (Temperature) وارد بازی میشه. دما یه عدده که مشخص میکنه مدل چقدر باید «خلاق» باشه و در انتخاب از این لیست احتمالات، ریسک کنه.
راهنمای تنظیم دما (دکمه خلاقیت)
- 🌡️ دمای صفر (0): حالت ربات دقیق. مدل هیچ ریسکی نمیکنه و همیشه محتملترین گزینه رو انتخاب میکنه. این حالت برای کارهایی که نیاز به جواب دقیق و قطعی دارن (مثل خلاصهسازی یه متن حقوقی) عالیه.
- 🌡️ دمای پایین (0.1 تا 0.4): یه کم خلاقیت. اگه یه گزینه دیگه هم خیلی محتمل باشه، مدل شانس کمی به اون هم میده. برای وقتی خوبه که چندتا جواب جایگزین ولی نزدیک به هم بخواید.
- 🌡️ دمای متوسط (0.5 تا 0.7): ریسکپذیری بیشتر. مدل حاضره گزینههایی که احتمال کمتری دارن رو هم انتخاب کنه. برای وقتی خوبه که دنبال ایدههای متنوع و طوفان فکری هستید.
- 🌡️ دمای یک (1): حالت آینه. خروجی مدل دقیقاً آینه احتمالات دادههای آموزشی میشه. یعنی اگه تو آموزشش دیده باشه که بعد از «یک، دو»، ۵۱٪ مواقع «سه» میاد و ۳۱٪ مواقع «سگ»، تو خروجیهاش هم همین نسبت رو رعایت میکنه.
- 🌡️ دمای بالاتر از یک (>1): حالت مستی! 🥴 اینجا مدل خیلی تصادفی و غیرقابل پیشبینی میشه. جوابهاش عجیب و غریب و اغلب پر از اشتباه میشن. چون مدل از اشتباهات خودش الگوبرداری میکنه و اوضاع لحظه به لحظه بدتر میشه!
پس بالاخره دمای بالا یا پایین؟
این یه بدهبستانه. هیچکدوم برتر مطلق نیستن:
- دمای پایین: جوابهای صحیحتر، قابل پیشبینیتر و تکرارپذیرتر. ✅
- دمای بالا: جوابهای متنوعتر، خلاقانهتر و جایگزینهای بیشتر. ✨
با تنظیم دما، میتونیم از گیر کردن مدل تو الگوهای تکراری جلوگیری کنیم و جوابهای جالبتری بگیریم.
🧅 رسیدیم به هسته اصلی پیاز: مغز هوش مصنوعی چطور کار میکنه؟
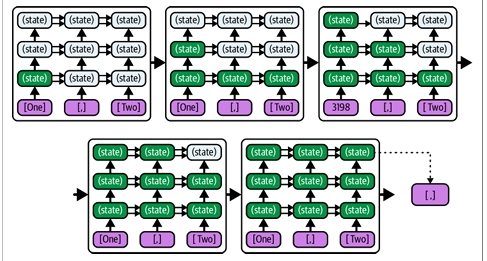
خب، وقتشه که آخرین لایه پیاز رو برداریم و مستقیم به مغز LLM نگاه کنیم. وقتی این لایه رو برمیدارید، با یه صحنه جالب روبرو میشید: این اصلاً یه مغز واحد نیست! بلکه شبیه به یک اتاق جلسه بزرگ پر از متخصصهای مختلفه! 👨🏫👩💻👨🎨👩🔬
معماری اصلی تمام LLMهای مدرن، ترنسفورمر (Transformer) نام داره. این معماری رو مثل یک جلسه تیمی در نظر بگیرید:
- برای هر کلمه (توکن) در جمله شما، یک متخصص استخدام میشه.
- همه این متخصصها با هم در یک جلسه چند مرحلهای (که بهش میگن لایه - Layer) شرکت میکنن.
- هدف جلسه اینه که در نهایت، کلمه بعدی جمله رو حدس بزنن.
وظیفه هر متخصص در جلسه چیه؟
هر متخصص (یا همون مغز کوچولو) دو تا وظیفه اصلی داره:
- گوش دادن و یاد گرفتن: هر متخصص به حرفهای متخصصهای قبل از خودش گوش میده تا درک بهتری از جمله پیدا کنه.
- کمک کردن به بقیه: هر متخصص، برداشت و تحلیل خودش رو در اختیار متخصصهای بعد از خودش قرار میده تا اونها هم درک بهتری پیدا کنن.
در نهایت، آخرین متخصص در صف، با استفاده از تمام اطلاعاتی که در جلسه رد و بدل شده، وظیفه داره که کلمه بعدی جمله رو حدس بزنه و اعلام کنه!
بعد از اینکه کلمه جدید حدس زده شد، یه متخصص جدید برای اون کلمه استخدام میشه، به انتهای صف اضافه میشه و کل فرآیند جلسه دوباره تکرار میشه تا کلمه بعدی و بعدی و بعدی حدس زده بشن.
مکانیزم توجه: متخصصها چطور با هم حرف میزنن؟ 🗣️
اینکه متخصصها چطور اطلاعات رو بین هم رد و بدل میکنن، مهمترین نوآوری معماری ترنسفورمره. به این فرآیند میگن «مکانیزم توجه» (Attention Mechanism). این مکانیزم شبیه یه بازی پرسش و پاسخ خیلی کارآمده:
فرض کنید جمله ما اینه: «گربه من روی مبل خوابیده، چون خسته بود.»
- ❓ سوال (Query): متخصصِ کلمه «بود» میخواد بدونه فاعل این فعل کیه. پس بلند میپرسه: «کی خسته بود؟»
- 💡 سرنخ (Key): همه متخصصهای دیگه به این سوال گوش میدن. متخصصِ کلمه «گربه» با خودش میگه: «عه! این سوال انگار به من ربط داره! من یه اسم هستم.»
- 🤝 جفتسازی (Matching): سیستم، سوالِ «کی خسته بود؟» رو با بهترین سرنخ یعنی «گربه» جفت میکنه.
- ✅ جواب (Value): حالا متخصصِ کلمه «بود» میفهمه که فاعلش «گربه» است و درک کاملی از جمله پیدا میکنه.
این فرآیند به صورت همزمان برای هزاران سوال و جواب در هر مرحله اتفاق میافته و باعث میشه مدل بتونه روابط پیچیده بین کلمات دور از هم رو هم درک کنه.
یک قانون مهم در جلسه: نگاه فقط به عقب! (Masking)
در این جلسات تیمی (ترنسفورمرها)، یک قانون خیلی مهم و عجیب وجود داره: هر متخصص فقط میتونه از متخصصهای سمت چپ خودش (یعنی کلمات قبلی) سوال بپرسه و اطلاعات بگیره. هیچ متخصصی حق نداره به سمت راست خودش نگاه کنه و از کلمات بعدی خبردار بشه! به همین خاطر به این مدلها میگن «ترنسفورمرهای یکطرفه» (Unidirectional). اطلاعات فقط از چپ به راست حرکت میکنه.
این ساختار یکطرفه، دو تا نتیجه خیلی مهم و کاربردی برای ما داره:
نتیجه ۱: سرعت پردازش پرامپت در مقابل تولید جواب
چون متخصصها میتونن به صورت موازی از همکاران سمت چپ خودشون اطلاعات بگیرن، پردازش پرامپت شما (که از قبل مشخصه) خیلی سریع انجام میشه. اما وقتی نوبت به تولید جواب میرسه، مدل باید منتظر بمونه تا هر کلمه جدید تولید بشه و بعد فرآیند رو برای کلمه بعدی شروع کنه. به خاطر همینه که:
LLMها در «خواندن» یک پرامپت طولانی، بسیار سریعتر از «نوشتن» یک جواب طولانی هستند!
نتیجه ۲: اهمیت حیاتی ترتیب در پرامپت!
این ساختار یکطرفه (نگاه فقط به عقب) یه پیام خیلی مهم برای ما داره: ترتیب نوشتن دستورات در پرامپت، مرگ و زندگیه!
بیاید یه مثال بزنیم. من همین فصل رو تا اینجا به ChatGPT دادم و در آخرش ازش پرسیدم:
«پاراگراف دقیقاً بالای این سوال، چند کلمه دارد؟»
جوابش چی بود؟ «۳۴۸ کلمه.» که یه جواب افتضاح و پرت بود!
چرا؟ چون وقتی متخصصهای مدل داشتن اون پاراگراف رو برای اولین و آخرین بار میخوندن، اصلاً نمیدونستن که قراره در ادامه ازشون سوال «تعداد کلمات» پرسیده بشه! اونها داشتن روی معنی، لحن و استایل تمرکز میکردن و حواسشون به شمردن کلمات نبود. چون مدل فقط میتونه به عقب نگاه کنه، وقتی به سوال میرسه دیگه نمیتونه برگرده و پاراگراف قبلی رو دوباره با دقت بشمره.
اما وقتی من همین سوال رو در ابتدای پرامپت پرسیدم... خب، باز هم جوابش دقیق نبود (چون شمردن برای LLMها سخته)، ولی خیلی خیلی نزدیکتر شد و گفت ۱۷۳ کلمه!
💡 یک قانون طلایی برای سنجش توانایی LLM
اگه میخواید بدونید آیا یه کاری رو میشه از LLM خواست یا نه، این سوال رو از خودتون بپرسید:
«آیا یک انسان متخصص که همه اطلاعات لازم رو از حفظ بلده، میتونه این پرامپت رو فقط با یک بار خوندن، بدون برگشت به عقب، بدون ویرایش و بدون یادداشتبرداری کامل کنه؟»
اگه جواب این سوال «بله» بود، به احتمال زیاد LLM هم از پسش برمیاد. اگه «نه»، احتمالاً باید پرامپتتون رو هوشمندانهتر طراحی کنید.





